
Sportvorhersagen
Ladevorgang...
Ladevorgang...
Stellen Sie sich vor, Sie könnten ein Fußballspiel nicht einmal, sondern zehntausendmal spielen lassen. Jedes Mal mit leicht anderen Zufällen, anderen Entscheidungen, anderen Wendungen. Am Ende hätten Sie nicht ein Ergebnis, sondern eine Verteilung von Ergebnissen. Sie wüssten, wie oft das Heimteam gewinnt, wie oft der Außenseiter eine Überraschung schafft, wie oft das Spiel torlos endet. Diese Idee ist das Kernprinzip simulationsbasierter Sportwetten-Prognosen.
Was nach Science-Fiction klingt, ist längst Realität. Große Datenanbieter wie Opta lassen ihre Supercomputer genau das tun: Spiele virtuell durchspielen, tausende Male, mit allen verfügbaren Informationen als Input. Das Ergebnis sind Wahrscheinlichkeiten, die nicht aus statischen Formeln stammen, sondern aus der Aggregation vieler simulierter Spielverläufe. Diese Methode hat einen Namen, der in der Wissenschaft seit Jahrzehnten bekannt ist: Monte-Carlo-Simulation.
Dieser Artikel erklärt, wie simulationsbasierte Prognosen funktionieren, worin ihre Stärken und Schwächen liegen und wie man als Nutzer mit ihren Ergebnissen umgehen sollte. Wir werden sehen, dass Simulationen mächtige Werkzeuge sind, aber auch ihre eigenen Tücken haben. Wer sie versteht, kann ihre Ergebnisse besser einordnen als jemand, der sie als Black Box betrachtet.
Das Prinzip der Monte-Carlo-Simulation
Der Name Monte-Carlo-Simulation stammt aus dem Zweiten Weltkrieg, als Wissenschaftler am Manhattan-Projekt nach Methoden suchten, komplexe physikalische Prozesse zu berechnen. Der Mathematiker Stanislaw Ulam erkannte, dass man statt analytischer Lösungen auch Zufallsexperimente nutzen konnte. Sein Onkel, so die Legende, musste regelmäßig nach Monte Carlo fahren, um zu spielen, und so war der Name geboren.
Die Grundidee ist bestechend einfach. Wenn ein Problem zu komplex für eine direkte Berechnung ist, simuliert man es viele Male mit zufälligen Eingaben und beobachtet, was herauskommt. Die Häufigkeit, mit der ein bestimmtes Ergebnis auftritt, nähert sich der tatsächlichen Wahrscheinlichkeit an, wenn man nur genug Simulationen durchführt. Das Gesetz der großen Zahlen garantiert diese Konvergenz.
Für Fußballspiele bedeutet das: Statt zu berechnen, dass Team A mit 58 Prozent Wahrscheinlichkeit gewinnt, lässt man das Spiel virtuell ablaufen. In jeder Simulation werden Ereignisse wie Torchancen, Schüsse und Tore gemäß bestimmter Wahrscheinlichkeiten generiert. Nach zehntausend Simulationen zählt man, wie oft Team A gewonnen hat. Wenn es 5.800 von 10.000 Mal gewonnen hat, beträgt die geschätzte Siegwahrscheinlichkeit 58 Prozent.
Der Vorteil gegenüber analytischen Methoden liegt in der Flexibilität. Eine Simulation kann beliebig komplexe Szenarien abbilden. Sie kann berücksichtigen, dass Teams nach einer Führung anders spielen, dass Platzverweise die Dynamik verändern, dass Spieler unterschiedliche Qualitäten haben. All das in einer Formel zu erfassen wäre extrem aufwendig. In einer Simulation ist es eine Frage der Modellierung.
Wie eine Fußball-Simulation aufgebaut ist
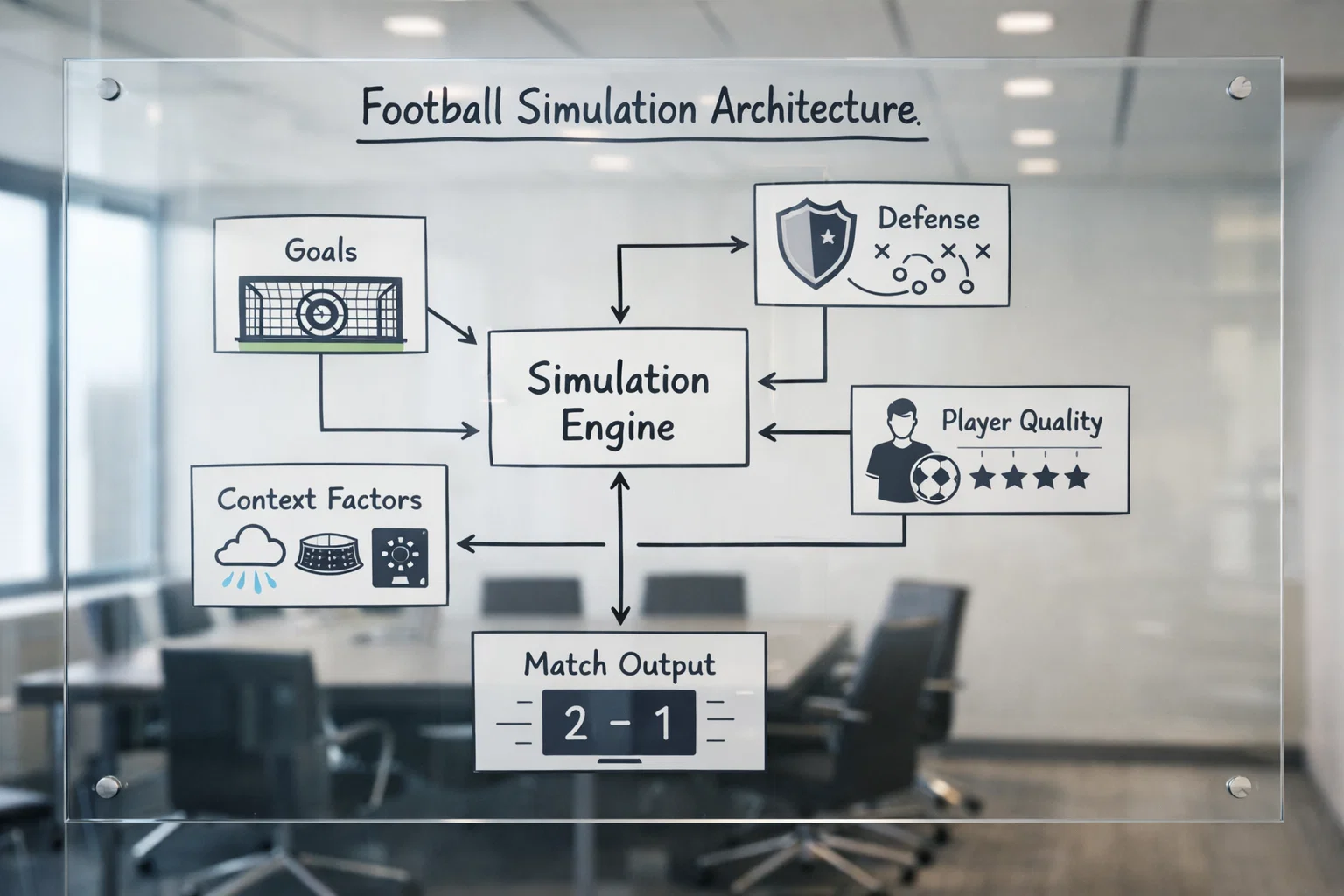
Eine Fußball-Simulation ist im Kern ein Modell dessen, was in neunzig Minuten passieren kann. Dieses Modell besteht aus verschiedenen Komponenten, die zusammenwirken, um ein virtuelles Spiel zu erzeugen.
Die grundlegendste Komponente ist die Torerzielung. Sie basiert typischerweise auf Expected-Goals-Daten. Wenn ein Team in der laufenden Saison durchschnittlich 1,8 Expected Goals pro Spiel erzeugt, verwendet die Simulation diesen Wert als Grundlage. In jedem virtuellen Spiel werden Torchancen generiert, deren Anzahl und Qualität von den historischen Daten abhängt.
Die nächste Schicht betrifft die individuelle Qualität. Nicht jede Torchance wird verwandelt, und verschiedene Spieler haben unterschiedliche Abschlussqualitäten. Fortschrittliche Simulationen berücksichtigen, wer wahrscheinlich auf dem Platz steht und wie gut dieser Spieler Chancen verwertet. Ein Elfmeter mit Erling Haaland am Punkt hat eine andere Erfolgswahrscheinlichkeit als einer mit einem Reservisten.
Die Defensivstärke bildet das Gegengewicht. Sie bestimmt, wie viele und welche Chancen der Gegner überhaupt kreiert. Ein Team mit einer starken Defensive lässt weniger hochwertige Chancen zu, was die simulierten Torchancen des Gegners reduziert. Die Interaktion zwischen Offensive und Defensive beider Teams ergibt die Spielcharakteristik.
Zusätzliche Faktoren wie Heimvorteil, Spielstand-Dynamik und Spielphase können eingebaut werden. Der Heimvorteil erhöht typischerweise die Offensivstärke des Heimteams leicht. Die Spielstand-Dynamik berücksichtigt, dass Teams nach einer Führung oft defensiver spielen. Die Spielphase modelliert, dass Tore in bestimmten Phasen wahrscheinlicher sind als in anderen.
Am Ende jeder Simulation steht ein konkretes Ergebnis: 2:1, 0:0, 3:2. Dieses Ergebnis ist ein Produkt aller simulierten Ereignisse und der Zufallszahlen, die den Ablauf gesteuert haben. Es repräsentiert einen möglichen Spielverlauf, nicht die Vorhersage dessen, was tatsächlich passieren wird.
Die Inputdaten: Wovon die Simulation abhängt
Eine Simulation ist nur so gut wie ihre Eingangsdaten. Der berühmte Informatiker-Spruch Garbage in, garbage out gilt hier uneingeschränkt. Welche Daten fließen typischerweise in eine Fußball-Simulation ein?
An erster Stelle stehen die Leistungsdaten der Teams. Dazu gehören Expected Goals für und gegen, Schussstatistiken, Ballbesitzwerte, Pressing-Intensität und viele weitere Metriken. Diese Daten werden typischerweise aus den letzten Spielen aggregiert, wobei jüngere Spiele höher gewichtet werden als ältere. Der genaue Aggregationszeitraum und die Gewichtung sind Entscheidungen des Modelldesigners.
Spielerdaten ergänzen die Teamdaten. Die erwartete Aufstellung bestimmt, welche individuellen Qualitäten zur Verfügung stehen. Verletzungen und Sperren reduzieren die Optionen. Formkurven einzelner Spieler können die simulierte Leistung beeinflussen. Je detaillierter die Spielerdaten, desto präziser kann die Simulation sein.
Kontextfaktoren bilden die dritte Kategorie. Der Heimvorteil ist historisch quantifiziert, aber er variiert zwischen Stadien und Wettbewerben. Die Bedeutung des Spiels beeinflusst die Motivation. Reisebelastung und Spielplanenge können die Fitness beeinträchtigen. Wetterbedingungen könnten theoretisch einbezogen werden, werden aber oft vernachlässigt.
Die Herausforderung liegt in der Auswahl und Gewichtung. Nicht alle verfügbaren Daten sind relevant, und mehr Daten bedeuten nicht automatisch bessere Prognosen. Ein überkomplexes Modell kann überangepasst sein und bei neuen Spielen versagen. Die Kunst liegt in der Balance zwischen Detailreichtum und Robustheit.
Für die Champions League kommen spezifische Überlegungen hinzu. Die teilnehmenden Teams spielen in unterschiedlichen Ligen mit verschiedenen Spielstilen. Ein direkter Vergleich der Ligadaten ist problematisch, weil die Gegner unterschiedlich stark sind. Simulationen müssen diese Niveauunterschiede berücksichtigen, was zusätzliche Annahmen erfordert.
Der Supercomputer-Mythos: Was steckt wirklich dahinter?
Wenn Anbieter von Supercomputer-Prognosen sprechen, schwingt ein gewisser technologischer Mystizismus mit. Der Begriff suggeriert enorme Rechenpower und entsprechende Präzision. Aber was steckt wirklich dahinter?
Zunächst zur Rechenleistung: Zehntausend Simulationen eines Fußballspiels sind für moderne Computer keine Herausforderung. Ein gewöhnlicher Laptop schafft das in Sekunden. Die Bezeichnung Supercomputer ist daher meist Marketing. Was zählt, ist nicht die Hardware, sondern die Software, also das Modell, das hinter den Simulationen steht.
Die eigentliche Komplexität liegt in der Modellentwicklung. Ein gutes Simulationsmodell zu bauen, erfordert jahrelange Arbeit, umfangreiche Daten und kontinuierliche Verfeinerung. Anbieter wie Opta beschäftigen Teams von Datenanalysten und Ingenieuren, die ihre Modelle pflegen und verbessern. Der Wert liegt in dieser intellektuellen Arbeit, nicht in der Rechenleistung.
Die Qualitätsunterschiede zwischen Anbietern sind erheblich. Ein einfaches Modell, das nur auf historischen Ergebnissen basiert, liefert andere Prognosen als ein ausgefeiltes System mit detaillierten Spielerdaten und situativen Anpassungen. Beide können als simuliert bezeichnet werden, aber ihre Aussagekraft ist völlig unterschiedlich.
Für Nutzer bedeutet das: Die Bezeichnung Supercomputer-Prognose ist kein Qualitätsmerkmal. Entscheidend ist, welche Daten einfließen, wie das Modell aufgebaut ist und wie es in der Vergangenheit performt hat. Ein transparenter Anbieter legt diese Informationen offen. Ein intransparenter versteckt sich hinter dem Supercomputer-Label.
Die Skepsis sollte besonders groß sein bei Anbietern, die extreme Genauigkeitsversprechen machen. Kein Modell, egal wie ausgefeilt, kann Fußballspiele mit 80 oder 90 Prozent Trefferquote vorhersagen. Wer das behauptet, lügt oder definiert Trefferquote sehr kreativ. Seriöse Anbieter kommunizieren ihre Grenzen ebenso wie ihre Stärken.
Stärken simulationsbasierter Prognosen

Simulationen haben gegenüber anderen Prognosemethoden spezifische Vorteile, die sie für bestimmte Anwendungen besonders geeignet machen.
Der erste Vorteil ist die Flexibilität. Eine Simulation kann beliebig komplexe Szenarien abbilden, solange sie sich modellieren lassen. Wenn man verstehen will, wie sich die Wahrscheinlichkeiten ändern, wenn ein bestimmter Spieler ausfällt, kann man die Simulation entsprechend anpassen und erneut laufen lassen. Diese What-if-Analysen sind mit analytischen Methoden oft nicht möglich.
Der zweite Vorteil ist die intuitive Interpretierbarkeit. Die Aussage In 58 von 100 simulierten Spielen gewinnt Team A ist leichter zu verstehen als eine abstrakte Wahrscheinlichkeit von 58 Prozent. Die Simulation macht die Unsicherheit greifbar und verdeutlicht, dass auch ein klarer Favorit oft verliert.
Der dritte Vorteil liegt in der Erfassung von Abhängigkeiten. In der Realität sind Ereignisse in einem Fußballspiel nicht unabhängig. Ein frühes Tor verändert das Spielgeschehen, ein Platzverweis noch mehr. Simulationen können diese Abhängigkeiten modellieren, indem sie den Spielverlauf sequenziell generieren und Ereignisse voneinander abhängig machen.
Der vierte Vorteil ist die Erzeugung von Nebenprognosen. Eine Simulation liefert nicht nur Sieger, sondern auch detaillierte Informationen über mögliche Spielverläufe. Die Verteilung der Tore, die Wahrscheinlichkeit für bestimmte Halbzeitstände, die Häufigkeit von Über- oder Unterszenarien, all das fällt als Nebenprodukt ab.
Besonders wertvoll ist die Kombination dieser Vorteile. Eine Simulation kann gleichzeitig komplex, interpretierbar und reichhaltig sein. Sie ermöglicht einen ganzheitlichen Blick auf ein Spiel, der über einfache Siegprognosen hinausgeht.
Schwächen und Grenzen von Simulationen
Keine Methode ist perfekt, und Simulationen haben ihre eigenen Schwächen, die man kennen sollte.
Die fundamentalste Schwäche ist die Abhängigkeit vom Modell. Eine Simulation produziert nur das, was das zugrunde liegende Modell erlaubt. Wenn das Modell bestimmte Faktoren nicht berücksichtigt, können sie auch nicht in den Simulationsergebnissen auftauchen. Ein Modell ohne Motivationsfaktor wird die besondere Bedeutung eines Derbys nicht erfassen. Ein Modell ohne taktische Komponente wird Überraschungen durch unerwartete Aufstellungen nicht vorhersagen.
Die zweite Schwäche betrifft die Scheinpräzision. Wenn eine Simulation 10.000 Durchläufe produziert und dabei 5.823 Heimsiege zählt, könnte man versucht sein, eine Siegwahrscheinlichkeit von 58,23 Prozent anzugeben. Diese Präzision ist jedoch Illusion. Die tatsächliche Unsicherheit liegt viel höher, weil das Modell selbst unsicher ist. Die vielen Simulationen reduzieren nur den Stichprobenfehler, nicht den Modellfehler.
Die dritte Schwäche liegt in der Sensitivität gegenüber Annahmen. Kleine Änderungen an den Inputparametern können große Änderungen in den Ergebnissen bewirken. Wenn man die erwarteten Tore eines Teams von 1,8 auf 2,0 erhöht, verschieben sich die Siegwahrscheinlichkeiten merklich. Diese Sensitivität bedeutet, dass die Prognosen stark davon abhängen, wie die Inputdaten geschätzt wurden.
Die vierte Schwäche betrifft seltene Ereignisse. Platzverweise, Elfmeter, Verletzungen von Schlüsselspielern während des Spiels sind selten, aber folgenreich. Eine Simulation kann solche Ereignisse einbauen, aber ihre Modellierung ist schwierig. Die Wahrscheinlichkeit eines Platzverweises mag historisch bei 5 Prozent liegen, aber welches Team den Platzverweis erhält und in welcher Spielminute, ist weitgehend Zufall.
Schließlich gibt es die grundsätzliche Grenze aller Prognosen: Fußball ist inhärent unvorhersehbar. Selbst eine perfekte Simulation würde keine perfekten Vorhersagen liefern, weil der Sport Zufallselemente enthält, die sich prinzipiell nicht vorhersagen lassen. Die Simulation quantifiziert diese Unsicherheit, eliminiert sie aber nicht.
Die 45-Prozent-Frage: Was Wahrscheinlichkeiten wirklich bedeuten
Wenn ein Simulationsanbieter verkündet, dass Team A mit 45 Prozent Wahrscheinlichkeit gewinnt, was bedeutet das konkret? Diese Frage ist weniger trivial, als sie scheint.
Die mathematische Interpretation ist klar: In 45 von 100 simulierten Spielen hat Team A gewonnen. Aber was sagt das über das reale Spiel, das nur einmal stattfindet? Das Spiel wird nicht hundertmal wiederholt werden. Es wird einmal gespielt, und entweder gewinnt Team A oder nicht. Die 45 Prozent sind keine Eigenschaft des realen Spiels, sondern eine Aussage über unser Wissen.
Eine hilfreiche Denkweise ist die frequentistische: Wenn wir viele Spiele mit ähnlichen Ausgangsbedingungen betrachten, sollte der Favorit in etwa so oft gewinnen, wie seine Wahrscheinlichkeit vorhersagt. Ein Team mit 45 Prozent sollte also langfristig etwa 45 Prozent seiner Spiele gewinnen, wenn die Prognosen korrekt kalibriert sind.
Für die Einzelentscheidung bedeutet das: Eine 45-Prozent-Chance ist nicht vernachlässigbar. Sie bedeutet, dass der Ausgang offen ist, dass der Gegner realistische Chancen hat, dass Überraschungen jederzeit möglich sind. Die Zahl quantifiziert die Unsicherheit, aber sie beseitigt sie nicht.
Die praktische Konsequenz für Wettende ist, dass Wahrscheinlichkeiten keine Handlungsanweisungen sind. Eine 45-Prozent-Siegchance macht eine Wette nicht automatisch gut oder schlecht. Entscheidend ist das Verhältnis zur angebotenen Quote. Wenn die Quote eine implizite Wahrscheinlichkeit von 35 Prozent hat, könnte Value vorliegen. Wenn sie 50 Prozent impliziert, ist die Wette vermutlich unattraktiv.
Ein häufiger Fehler ist die Überinterpretation kleiner Differenzen. Eine 48-Prozent-Prognose ist praktisch nicht unterscheidbar von einer 52-Prozent-Prognose. Die Unsicherheit der Modelle selbst macht solche Feinheiten irrelevant. Erst bei deutlichen Abweichungen, etwa 60 Prozent versus 40 Prozent, werden die Unterschiede aussagekräftig.
Opta und die Industriestandards

Opta ist einer der bekanntesten Anbieter von Fußballdaten und -analysen. Ihre simulationsbasierten Prognosen gelten als Industriestandard und verdienen eine nähere Betrachtung.
Das Opta-Modell basiert auf dem sogenannten Supercomputer, der für jedes Spiel 10.000 Simulationen durchführt. Die Eingangsdaten umfassen eine breite Palette von Metriken: Expected Goals, Schussqualität, Defensivstärke, Heimvorteil und mehr. Die genauen Details sind proprietär, aber die Grundprinzipien sind bekannt.
Ein Merkmal des Opta-Ansatzes ist die kontinuierliche Aktualisierung. Die Modelle werden regelmäßig an neue Daten angepasst, und die Prognosen werden bis kurz vor Spielbeginn aktualisiert, wenn neue Informationen wie Aufstellungen bekannt werden. Diese Aktualität ist ein Qualitätsmerkmal, das nicht alle Anbieter bieten.
Die Validierung der Opta-Prognosen zeigt, dass sie gut kalibriert sind. Spiele, die mit 60 Prozent für den Favoriten prognostiziert werden, enden tatsächlich in etwa 60 Prozent der Fälle mit einem Favoritensieg. Diese Kalibrierung ist ein wichtiges Qualitätsmerkmal, das zeigt, dass das Modell die Realität angemessen abbildet.
Dennoch ist Opta nicht unfehlbar. Wie alle Modelle hat auch das Opta-System seine blinden Flecken. Motivationsfaktoren, taktische Überraschungen, Tagesform von Spielern sind schwer zu quantifizieren und fließen nur indirekt ein. Die Prognosen sind gut, aber sie sind keine Gewissheiten.
Für Nutzer ist Opta ein sinnvoller Referenzpunkt. Wenn die eigene Einschätzung stark von der Opta-Prognose abweicht, sollte man sich fragen, warum. Vielleicht hat man etwas erkannt, was das Modell übersehen hat. Vielleicht hat man aber auch selbst etwas übersehen. Der Vergleich zwingt zur kritischen Reflexion.
DIY: Eigene einfache Simulationen erstellen
Wer die Prinzipien der Simulation verstehen will, kann mit einfachen eigenen Modellen experimentieren. Das erfordert keine Programmierkenntnisse, nur eine Tabellenkalkulation und etwas Geduld.
Der einfachste Ansatz basiert auf der Poisson-Verteilung. Man schätzt die erwarteten Tore für beide Teams, etwa aus den xG-Daten der letzten Spiele. Dann generiert man Zufallszahlen, die gemäß der Poisson-Verteilung verteilt sind. Jede Zeile der Tabelle repräsentiert eine Simulation, das Ergebnis ist die Differenz der Zufallszahlen.
In einer Tabellenkalkulation könnte das so aussehen: Spalte A enthält die Zufallszahlen für die Heimtore, generiert mit einer Poisson-Funktion und dem erwarteten Heimtore-Wert. Spalte B analog für die Auswärtstoren. Spalte C berechnet das Ergebnis: Heimsieg, Unentschieden oder Auswärtssieg. Wenn man 1.000 Zeilen anlegt, hat man 1.000 Simulationen.
Die Auswertung ist dann einfach: Man zählt, wie oft Heimsieg, Unentschieden und Auswärtssieg auftreten, und teilt durch die Gesamtzahl. Das Ergebnis sind die geschätzten Wahrscheinlichkeiten. Sie werden von Durchlauf zu Durchlauf leicht variieren, weil die Zufallszahlen anders sind, aber bei genug Simulationen stabilisieren sie sich.
Dieses einfache Modell hat offensichtliche Schwächen. Es behandelt die Torerzielung der beiden Teams als unabhängig, ignoriert Spielverlaufs-Dynamiken und berücksichtigt keine individuellen Spielerqualitäten. Aber es vermittelt ein Grundverständnis für das Prinzip und kann mit Erweiterungen verfeinert werden.
Der Lerneffekt dieser Übung ist erheblich. Man versteht, wie sensibel die Ergebnisse auf die Eingangswerte reagieren. Man erkennt, dass 1.000 Simulationen oft nicht ausreichen, um stabile Ergebnisse zu erhalten. Und man begreift, warum professionelle Anbieter so viel Aufwand in ihre Modelle stecken.
Die Sensitivitätsanalyse: Wie robust sind Simulationsergebnisse?
Eine wichtige Frage bei jeder Simulation ist, wie empfindlich die Ergebnisse auf Änderungen der Eingangswerte reagieren. Diese Sensitivitätsanalyse ist entscheidend für die Einschätzung der Prognosequalität.
Das Prinzip ist einfach: Man variiert einen Eingangswert, hält alle anderen konstant und beobachtet, wie sich das Ergebnis verändert. Wenn eine kleine Änderung große Auswirkungen hat, ist das Ergebnis sensitiv gegenüber diesem Parameter. Wenn große Änderungen kaum Auswirkungen haben, ist das Ergebnis robust.
Im Fußballkontext sind die erwarteten Tore der sensitivste Parameter. Eine Erhöhung der erwarteten Heimtore von 1,5 auf 2,0 kann die Siegwahrscheinlichkeit um zehn oder mehr Prozentpunkte verschieben. Da die erwarteten Tore selbst geschätzt werden müssen, pflanzt sich ihre Unsicherheit direkt in die Prognose fort.
Die praktische Implikation ist, dass die Unsicherheit der Prognosen größer ist als die reine Simulationsstreuung. Selbst wenn man eine Million Simulationen durchführt, bleibt die Unsicherheit über die richtigen Eingangswerte bestehen. Diese Modellunsicherheit dominiert die Stichprobenunsicherheit bei weitem.
Seriöse Anbieter führen Sensitivitätsanalysen durch und berichten deren Ergebnisse, zumindest intern. Sie wissen, welche Parameter kritisch sind und wie groß die resultierende Unsicherheit ist. Für Nutzer ist es schwierig, diese Analysen nachzuvollziehen, aber man kann nach entsprechenden Informationen fragen oder auf Anbieter setzen, die ihre Methodik transparent machen.
Eine eigene informelle Sensitivitätsanalyse ist möglich, indem man Prognosen verschiedener Anbieter vergleicht. Wenn alle zu ähnlichen Ergebnissen kommen, sind die Prognosen wahrscheinlich robust. Wenn sie stark abweichen, ist die Unsicherheit hoch, und Vorsicht ist geboten.
Simulationen für verschiedene Wettmärkte
Simulationen liefern nicht nur Siegprognosen, sondern auch Informationen über andere Wettmärkte. Diese Nebenprodukte können wertvoller sein als die Hauptprognose.
Der Über-Unter-Markt fragt nach der Gesamtzahl der Tore. Eine Simulation, die einzelne Spielverläufe generiert, liefert automatisch die Verteilung der Toranzahlen. Die Wahrscheinlichkeit für über 2,5 Tore ist einfach der Anteil der Simulationen mit drei oder mehr Toren. Diese Prognose kann präziser sein als die Siegprognose, weil sie von einigen Faktoren weniger abhängt.
Der Both-Teams-to-Score-Markt profitiert ebenfalls von Simulationen. Die Wahrscheinlichkeit, dass beide Teams treffen, ergibt sich aus der Verteilung der Ergebnisse. Simulationen können hier Abhängigkeiten berücksichtigen, die einfache Modelle übersehen, etwa dass Teams nach einer Führung defensiver spielen und damit die Wahrscheinlichkeit für ein Gegentor senken.
Handicap-Märkte lassen sich direkt aus der Ergebnisverteilung ablesen. Wenn man wissen will, wie wahrscheinlich ein Sieg mit mindestens zwei Toren Differenz ist, zählt man einfach die entsprechenden Simulationen. Diese Information ist automatisch vorhanden und muss nicht separat berechnet werden.
Exotischere Märkte wie Tore in bestimmten Zeiträumen erfordern detailliertere Simulationen, die den Spielverlauf zeitlich auflösen. Nicht alle Modelle bieten diese Tiefe, aber die Prinzipien sind dieselben. Wenn die Simulation die zeitliche Struktur abbildet, fallen auch zeitbezogene Prognosen als Nebenprodukt ab.
Die Qualität dieser Nebenprognosen hängt davon ab, wie gut das Modell die entsprechenden Aspekte erfasst. Eine einfache Poisson-basierte Simulation liefert gute Über-Unter-Prognosen, aber keine zuverlässigen Aussagen über Tore in der letzten Viertelstunde. Für spezialisierte Märkte braucht man spezialisierte Modelle.
Simulationen versus reine Statistik: Wann ist was besser?
Simulationen sind nicht immer die beste Methode. In manchen Fällen liefern einfachere statistische Ansätze gleich gute oder sogar bessere Ergebnisse. Wann lohnt sich der Aufwand einer Simulation?
Simulationen sind überlegen, wenn die Situation komplex ist und mehrere interagierende Faktoren berücksichtigt werden müssen. Ein Spiel zwischen zwei gleichstarken Teams mit verschiedenen Spielstilen, unterschiedlichen Kaderproblemen und spezifischen taktischen Konstellationen ist ein guter Kandidat für eine Simulation. Die Flexibilität der Methode kommt hier zum Tragen.
Einfache Statistik ist ausreichend, wenn die Frage simpel ist und historische Daten reichlich vorhanden sind. Die Wahrscheinlichkeit, dass ein klarer Favorit zu Hause gegen einen Abstiegskandidaten gewinnt, lässt sich aus historischen Häufigkeiten ablesen, ohne dass eine aufwendige Simulation nötig wäre.
Der Aufwand-Nutzen-Aspekt spielt ebenfalls eine Rolle. Eine gute Simulation zu entwickeln, erfordert erhebliche Ressourcen. Für einen Gelegenheitsanalysten lohnt sich das nicht. Er ist besser beraten, auf bestehende Simulationsanbieter zurückzugreifen oder mit einfacheren Methoden zu arbeiten.
Die Qualität der verfügbaren Daten beeinflusst die Wahl. Simulationen sind datenintensiv. Wenn die Datenlage dünn ist, kann eine Simulation keine besseren Ergebnisse liefern als eine einfache Methode. In solchen Fällen versteckt die Komplexität der Simulation nur die Unsicherheit, ohne sie zu reduzieren.
Für die meisten Nutzer ist die praktische Empfehlung, Simulationsergebnisse von etablierten Anbietern zu nutzen und diese mit einfachen eigenen Analysen zu ergänzen. Die Kombination liefert oft bessere Ergebnisse als jeder Ansatz allein, weil verschiedene Perspektiven zusammenkommen.
Kritische Würdigung: Die Grenzen des Simulierbaren

Simulationen sind mächtige Werkzeuge, aber sie haben fundamentale Grenzen, die man nicht vergessen sollte.
Die erste Grenze ist das Modell selbst. Eine Simulation kann nur das abbilden, was der Modelldesigner vorgesehen hat. Wenn ein wichtiger Faktor nicht im Modell enthalten ist, kann er auch nicht in den Ergebnissen auftauchen. Die Simulation ist so klug wie ihr Ersteller, nicht klüger.
Die zweite Grenze betrifft die Datenqualität. Simulationen verarbeiten Daten, und wenn die Daten fehlerhaft oder unvollständig sind, sind es auch die Ergebnisse. Die Digitalisierung des Fußballs hat zwar zu einer Datenexplosion geführt, aber nicht alle Daten sind gleich zuverlässig. Schussdaten sind genauer als Pressing-Metriken, und beide sind genauer als subjektive Einschätzungen.
Die dritte Grenze ist die Unvorhersehbarkeit der Zukunft. Simulationen basieren auf vergangenen Mustern und nehmen an, dass diese Muster fortbestehen. Aber Teams verändern sich, Trainer lernen, Spieler entwickeln sich. Eine Simulation, die auf Daten der Vorsaison basiert, kann von der aktuellen Realität abweichen.
Die vierte Grenze ist die Rechenbarkeit menschlicher Faktoren. Motivation, Nervosität, Teamchemie, Tagesform sind schwer zu quantifizieren und noch schwerer zu simulieren. Ein Team, das nach einem Skandal unter besonderem Druck steht, wird vom Modell möglicherweise genauso behandelt wie eines in normaler Verfassung.
Die Konsequenz ist nicht, Simulationen abzulehnen, sondern sie angemessen einzuordnen. Sie sind Werkzeuge zur Strukturierung von Informationen und zur Quantifizierung von Unsicherheit. Sie sind keine Orakel, die die Zukunft vorhersagen. Wer sie mit dieser realistischen Erwartung nutzt, kann von ihnen profitieren.
Praktische Empfehlungen für den Umgang mit Simulationsprognosen
Nach all der Theorie stellt sich die Frage, wie man als Nutzer konkret mit Simulationsprognosen umgehen sollte.
Erstens: Die Quelle prüfen. Nicht alle Simulationen sind gleich. Man sollte wissen, wer die Prognose erstellt hat, welche Daten einfließen und wie das Modell in der Vergangenheit performt hat. Transparente Anbieter sind intransparenten vorzuziehen.
Zweitens: Die Unsicherheit beachten. Eine Prognose von 55 Prozent ist nicht sicher, sondern eine Schätzung mit erheblicher Unsicherheit. Die wahre Wahrscheinlichkeit könnte bei 50 oder 60 Prozent liegen. Diese Streuung sollte in Entscheidungen einfließen.
Drittens: Mit anderen Quellen abgleichen. Wenn die eigene Simulation stark von anderen Prognosen oder den Buchmacher-Quoten abweicht, sollte man nachforschen, warum. Vielleicht hat man etwas erkannt, vielleicht aber auch etwas übersehen.
Viertens: Die Prognose als Werkzeug nutzen, nicht als Anweisung. Die Simulation liefert Informationen, aber die Entscheidung trifft der Mensch. Faktoren, die das Modell nicht erfasst, können und sollten in die eigene Einschätzung einfließen.
Fünftens: Langfristig denken. Einzelne Prognosen können richtig oder falsch sein, ohne dass das viel über die Qualität des Modells aussagt. Erst über viele Spiele zeigt sich, ob ein Ansatz funktioniert. Geduld und systematische Dokumentation sind wichtiger als schnelle Urteile.
Sechstens: Realistisch bleiben. Selbst die besten Simulationen garantieren keinen Erfolg. Fußball ist zu komplex und zu zufallsbehaftet, um sicher vorhersagbar zu sein. Wer das akzeptiert, kann von Simulationen profitieren, ohne sich Illusionen hinzugeben.
Ausblick: Die Zukunft simulationsbasierter Prognosen
Die Technologie entwickelt sich weiter, und simulationsbasierte Prognosen werden in den kommenden Jahren noch leistungsfähiger werden. Einige Trends zeichnen sich ab.
Die Datenerfassung wird präziser. Tracking-Systeme erfassen die Position jedes Spielers mehrfach pro Sekunde. Diese Daten ermöglichen Simulationen, die individuelle Spielerbewegungen und taktische Muster abbilden, statt nur Teamaggregate zu verwenden. Die Modelle werden dadurch detaillierter und potentiell präziser.
Die Rechenleistung wird günstiger. Was heute Spezialhardware erfordert, wird morgen auf gewöhnlichen Computern laufen. Das ermöglicht komplexere Modelle mit mehr Simulationen und feinerer Auflösung. Die Demokratisierung der Technologie bringt fortschrittliche Methoden in die Reichweite von mehr Nutzern.
Die Integration von Echtzeitdaten wird zunehmen. Schon heute aktualisieren manche Anbieter ihre Prognosen während des Spiels, basierend auf dem laufenden Geschehen. In Zukunft könnten Simulationen in Echtzeit laufen und Live-Wettentscheidungen unterstützen.
Gleichzeitig werden auch die Buchmacher ihre Systeme verbessern. Der technologische Vorsprung, den Simulationen bieten könnten, wird schrumpfen, wenn alle Marktteilnehmer ähnliche Methoden nutzen. Der Wettmarkt wird effizienter, und die Möglichkeiten für systematische Überrenditen werden kleiner.
Für den einzelnen Nutzer bedeutet das: Die Grundprinzipien bleiben relevant, auch wenn die Details sich ändern. Wer heute lernt, Simulationen kritisch zu verstehen und sinnvoll zu nutzen, ist auch für die Zukunft gerüstet. Die Technologie mag sich wandeln, aber das statistische Denken dahinter bleibt.
Schlusswort: Simulationen als Teil des Werkzeugkastens

Simulationsbasierte Prognosen sind ein faszinierendes Werkzeug, das die Komplexität des Fußballs in quantifizierbare Wahrscheinlichkeiten übersetzt. Sie ermöglichen Analysen, die mit einfacheren Methoden nicht möglich wären, und liefern reichhaltige Informationen über mögliche Spielverläufe.
Aber sie sind keine Wundermittel. Sie basieren auf Modellen, die die Realität nur unvollständig abbilden. Sie verarbeiten Daten, die selbst unsicher sind. Und sie können die fundamentale Unvorhersehbarkeit des Sports nicht eliminieren, nur quantifizieren.
Der kluge Umgang mit Simulationen erfordert Verständnis ihrer Funktionsweise und Anerkennung ihrer Grenzen. Wer beides mitbringt, kann von ihnen profitieren. Wer sie als Black Box akzeptiert oder als Orakel missversteht, wird früher oder später enttäuscht werden.
Am Ende bleibt Fußball ein Spiel, dessen Ergebnisse erst feststehen, wenn der Schlusspfiff ertönt. Simulationen helfen, die Chancen einzuschätzen, aber sie entscheiden nicht das Spiel. Diese Unvorhersehbarkeit ist es, die den Sport spannend macht, und keine Simulation der Welt sollte das ändern wollen.