
Sportvorhersagen
Ladevorgang...
Ladevorgang...
Sechzig Prozent Siegwahrscheinlichkeit für Real Madrid. Diese Zahl wirkt auf den ersten Blick klar und eindeutig. Doch was bedeutet sie tatsächlich für jemanden, der auf das Spiel wetten möchte? Die Antwort ist komplexer als es scheint, und das Verständnis von Wahrscheinlichkeiten ist der Schlüssel zur sinnvollen Nutzung von KI-Tipps in der Champions League. Wer diese Zahlen missdeutet, läuft Gefahr, systematische Fehler zu machen, die langfristig teuer werden.
Die mathematischen Grundlagen hinter KI-Sportwetten-Prognosen wirken auf viele Nutzer abschreckend. Dabei sind die Konzepte durchaus zugänglich, wenn man sie von ihrem mathematischen Fachjargon befreit. Die Wahrscheinlichkeit eines Ereignisses ist im Kern nichts anderes als ein Maß dafür, wie oft dieses Ereignis unter vergleichbaren Bedingungen eintreten würde. Eine 60-prozentige Siegwahrscheinlichkeit bedeutet, dass Real Madrid bei 100 hypothetischen Wiederholungen dieses Spiels etwa 60-mal gewinnen würde. Das einzelne Spiel, auf das tatsächlich gewettet wird, kann natürlich auch mit einer 40-prozentigen Wahrscheinlichkeit anders ausgehen.
Der Weg von den Daten zur Wahrscheinlichkeit
Bevor eine KI eine Wahrscheinlichkeit für ein Champions-League-Spiel ausgeben kann, muss sie eine Fülle von Daten verarbeiten und in mathematische Modelle übersetzen. Dieser Prozess ist weniger mysteriös als es der Begriff künstliche Intelligenz vermuten lässt, aber er ist durchaus anspruchsvoll und beinhaltet mehrere Stufen der Transformation.
Am Anfang steht die Datensammlung. Für ein typisches Champions-League-Spiel fließen historische Ergebnisse beider Teams ein, ihre aktuellen Ligapositionen, Heim- und Auswärtsbilanzen, Torstatistiken und fortgeschrittene Metriken wie Expected Goals. Dazu kommen Informationen über den Kader, etwa Verletzungen und Sperren, sowie kontextuelle Faktoren wie Reisebelastung oder die Bedeutung des Spiels für die Gruppenkonstellation.
Diese Rohdaten müssen in einen vergleichbaren Rahmen gebracht werden. Ein Tor eines Bundesliga-Teams gegen Borussia Dortmund hat einen anderen Aussagewert als ein Tor eines portugiesischen Teams gegen einen Abstiegskandidaten. Die KI verwendet deshalb Stärkeratings, die die Leistung eines Teams relativ zum Liganiveau ausdrücken. Ein gängiger Ansatz ist das Elo-System, das ursprünglich für Schach entwickelt wurde und Teams basierend auf ihren Ergebnissen Punkte zuweist. Nach jedem Spiel werden die Ratings angepasst, wobei ein Sieg gegen ein starkes Team mehr Punkte bringt als einer gegen ein schwaches.
Aus den Stärkeratings lassen sich Erwartungswerte für Tore ableiten. Hier kommt die Poisson-Verteilung ins Spiel, eine mathematische Funktion, die sich für die Modellierung seltener Ereignisse eignet. Tore im Fußball sind solche seltenen Ereignisse: Im Durchschnitt fallen etwa 2,6 Tore pro Spiel, verteilt auf 90 Minuten. Die Poisson-Verteilung erlaubt es, aus der erwarteten Anzahl von Toren eine vollständige Wahrscheinlichkeitsverteilung für alle möglichen Ergebnisse zu berechnen.
Ein konkretes Beispiel verdeutlicht das Verfahren. Nehmen wir an, die KI schätzt, dass Bayern München in einem bestimmten Spiel im Durchschnitt 2,1 Tore erzielt und der Gegner 0,9 Tore. Mit der Poisson-Formel lässt sich nun berechnen, wie wahrscheinlich jedes einzelne Ergebnis ist. Die Wahrscheinlichkeit für genau zwei Bayern-Tore ergibt sich aus der Formel, indem der Erwartungswert 2,1 eingesetzt wird. Analog für alle anderen möglichen Torzahlen. Die Multiplikation der Einzelwahrscheinlichkeiten liefert dann die Wahrscheinlichkeit für jedes konkrete Spielergebnis.
Die Siegwahrscheinlichkeit ergibt sich aus der Summe aller Ergebniswahrscheinlichkeiten, bei denen das eine Team mehr Tore erzielt als das andere. Wenn Bayern beispielsweise mit 35 Prozent Wahrscheinlichkeit genau zwei Tore schießt und der Gegner mit 40 Prozent genau ein Tor, dann trägt das Ergebnis 2:1 mit einer Wahrscheinlichkeit von 35 mal 40, also 14 Prozent, zur Bayern-Siegwahrscheinlichkeit bei. Summiert man alle Bayern-Siege auf, erhält man die Gesamtwahrscheinlichkeit.
Die verschiedenen Arten von Wahrscheinlichkeiten in KI-Prognosen
KI-Systeme für Champions-League-Tipps produzieren nicht nur eine einzelne Zahl, sondern verschiedene Wahrscheinlichkeitstypen für unterschiedliche Wettmärkte. Das Verständnis dieser Differenzierung ist entscheidend für die praktische Anwendung.
Die Siegwahrscheinlichkeit im Dreiweg-Markt ist die bekannteste Form. Sie gibt an, wie wahrscheinlich ein Heimsieg, ein Unentschieden oder ein Auswärtssieg ist. Diese drei Wahrscheinlichkeiten müssen sich zu 100 Prozent addieren. Wenn die KI 45 Prozent für Heimsieg, 25 Prozent für Unentschieden und 30 Prozent für Auswärtssieg ausgibt, ist die Summe exakt 100 Prozent.
Torwahrscheinlichkeiten beziehen sich auf die Anzahl der gefallenen Tore, unabhängig davon, welches Team sie erzielt. Der Markt Über/Unter 2,5 Tore fragt, ob mehr oder weniger als drei Tore fallen. Die KI berechnet dafür die Wahrscheinlichkeit, dass die Summe beider Torzahlen bei 0, 1 oder 2 liegt, was dem Unter 2,5 entspricht, beziehungsweise bei 3 oder mehr, was dem Über 2,5 entspricht.
Ereigniswahrscheinlichkeiten betreffen spezifische Vorkommnisse im Spiel. Der Markt Beide Teams treffen fragt, ob jedes Team mindestens ein Tor erzielt. Die KI muss dafür berechnen, wie wahrscheinlich es ist, dass weder Team bei null Toren bleibt. Ähnlich funktionieren Prognosen für Halbzeit-Ergebnisse, Handikaps oder exakte Ergebnisse.
Ein wichtiger Punkt ist die unterschiedliche Genauigkeit verschiedener Wahrscheinlichkeitstypen. Siegwahrscheinlichkeiten lassen sich relativ robust schätzen, weil sie auf aggregierten Daten basieren. Exakte Ergebniswahrscheinlichkeiten sind hingegen deutlich unsicherer, weil sie von mehr Faktoren abhängen. Ein 2:1 erfordert eine sehr spezifische Kombination von Ereignissen, während ein Heimsieg auf viele verschiedene Weisen zustande kommen kann.
Die Granularität der Prognosen beeinflusst auch den potentiellen Mehrwert. Bei Siegwahrscheinlichkeiten sind die Schätzungen verschiedener KI-Systeme und auch der Buchmacher relativ ähnlich, weil alle auf dieselben grundlegenden Daten zugreifen. Bei exotischeren Märkten, etwa dem ersten Torschützen oder der Minutenspanne des ersten Tores, sind die Prognosen unsicherer, was theoretisch mehr Raum für Fehlbewertungen durch die Buchmacher lässt.
Mathematische Grundlagen verstehen: Poisson und darüber hinaus
Die Poisson-Verteilung ist das Arbeitspferd der Fußballprognose, aber sie hat ihre Grenzen. Ein tieferes Verständnis der mathematischen Grundlagen hilft dabei, die Aussagekraft von KI-Prognosen einzuschätzen.
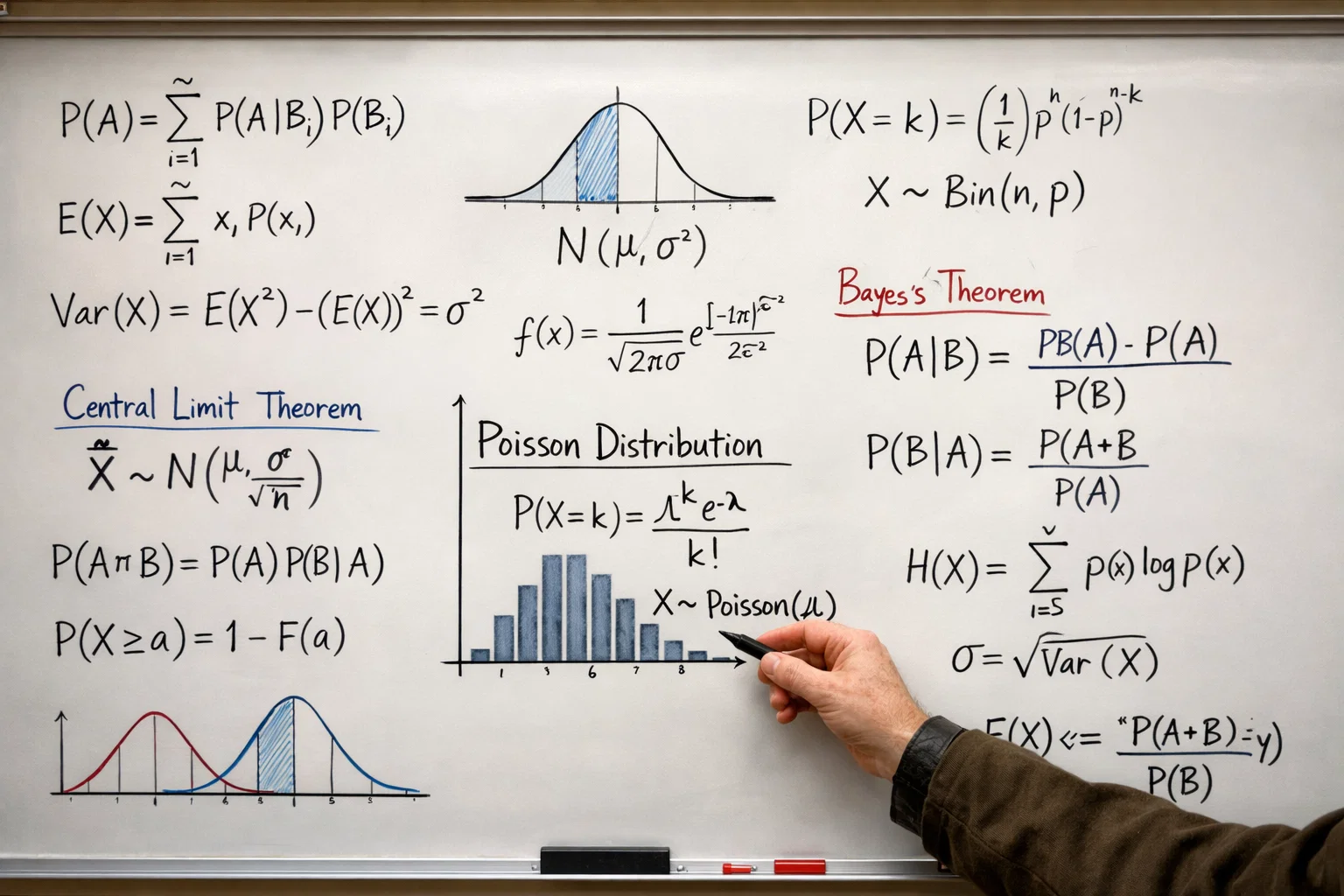
Die Stärke der Poisson-Verteilung liegt in ihrer Einfachheit. Sie benötigt nur einen einzigen Parameter, nämlich den Erwartungswert, um eine vollständige Wahrscheinlichkeitsverteilung zu generieren. Der französische Mathematiker Siméon Denis Poisson entwickelte diese Verteilung im 19. Jahrhundert zur Modellierung seltener Ereignisse. Sie eignet sich besonders gut für Situationen, in denen Ereignisse unabhängig voneinander mit konstanter Rate eintreten.
Im Fußball ist diese Annahme nur näherungsweise erfüllt. Tore fallen nicht unabhängig voneinander. Wenn ein Team führt, spielt es oft defensiver, während das zurückliegende Team mehr Risiko eingeht. Diese taktischen Anpassungen beeinflussen die Torwahrscheinlichkeiten im Spielverlauf. Außerdem ist die Rate nicht konstant: In den letzten Minuten eines engen Spiels fallen statistisch mehr Tore als zu Beginn, weil Teams alles nach vorne werfen.
Trotz dieser Einschränkungen liefert die Poisson-Verteilung erstaunlich gute Näherungen für Fußballergebnisse. Wissenschaftliche Untersuchungen haben gezeigt, dass die theoretischen Verteilungen gut mit den beobachteten Häufigkeiten übereinstimmen. Der Physiker Metin Tolan hat in seinen Analysen nachgewiesen, dass über 70 Prozent der Varianz in Bundesliga-Ergebnissen durch Zufall erklärt werden können, was die Anwendbarkeit der Poisson-Statistik stützt.
Fortgeschrittenere Modelle erweitern den Poisson-Ansatz auf verschiedene Weisen. Bivariate Poisson-Modelle berücksichtigen eine mögliche Korrelation zwischen den Torzahlen beider Teams. Wenn eine Mannschaft besonders offensiv spielt, erhöht das möglicherweise sowohl die eigenen als auch die gegnerischen Torchancen. Die Kovarianz zwischen beiden Torzahlen erfasst diesen Zusammenhang.
Hierarchische Bayes-Modelle gehen noch einen Schritt weiter und modellieren die Unsicherheit über die Modellparameter selbst. Statt anzunehmen, dass die Stärke eines Teams exakt bekannt ist, wird eine Verteilung über mögliche Stärken angenommen. Diese Verteilung wird mit jedem neuen Spielergebnis aktualisiert, was zu stabileren Langzeitprognosen führt.
Die Komplexität des Modells ist nicht automatisch ein Qualitätsmerkmal. Einfachere Modelle sind oft robuster und weniger anfällig für Überanpassung an historische Daten. Ein Modell mit vielen Parametern kann die Vergangenheit perfekt erklären, aber bei neuen Daten versagen. Die Kunst liegt darin, das richtige Maß an Komplexität zu finden.
Von der Wahrscheinlichkeit zur fairen Quote
Die Verbindung zwischen Wahrscheinlichkeiten und Wettquoten ist fundamental für jeden, der KI-Tipps praktisch nutzen möchte. Eine Wahrscheinlichkeit allein sagt noch nichts darüber aus, ob eine Wette sinnvoll ist. Entscheidend ist das Verhältnis zwischen der geschätzten Wahrscheinlichkeit und der angebotenen Quote.
Die Umrechnung von Wahrscheinlichkeiten in Quoten folgt einer einfachen Formel: Die faire Quote ist der Kehrwert der Wahrscheinlichkeit. Wenn die KI eine Siegwahrscheinlichkeit von 50 Prozent schätzt, entspricht das einer fairen Quote von 2,0. Bei 60 Prozent wäre die faire Quote etwa 1,67, bei 40 Prozent etwa 2,5.

Diese faire Quote berücksichtigt allerdings noch nicht die Gewinnmarge des Buchmachers. In der Praxis bieten Buchmacher niedrigere Quoten an, als die fairen Wahrscheinlichkeiten ergeben würden. Die Differenz ist die Marge, oft auch Vig oder Juice genannt. Bei einem typischen Champions-League-Spiel liegt die Marge bei etwa fünf bis zehn Prozent. Das bedeutet, dass die Summe der impliziten Wahrscheinlichkeiten, die sich aus den Quoten ergeben, bei 105 bis 110 Prozent liegt statt bei 100 Prozent.
Die implizite Wahrscheinlichkeit einer Quote berechnet sich als Kehrwert der Quote. Eine Quote von 2,0 impliziert 50 Prozent, eine Quote von 3,0 impliziert 33 Prozent. Durch den Vergleich der KI-Wahrscheinlichkeit mit der impliziten Quotenwahrscheinlichkeit lässt sich erkennen, ob eine Wette potentiell profitabel ist.
Ein Beispiel: Die KI schätzt die Siegwahrscheinlichkeit von Manchester City auf 65 Prozent. Der Buchmacher bietet eine Quote von 1,60, was einer impliziten Wahrscheinlichkeit von 62,5 Prozent entspricht. Die KI-Schätzung liegt über der impliziten Wahrscheinlichkeit, was auf einen Value Bet hindeuten könnte. Allerdings ist die Differenz von 2,5 Prozentpunkten klein genug, dass sie auch auf Schätzunsicherheit zurückzuführen sein könnte.
Die Identifikation profitabler Wetten erfordert daher nicht nur genaue Wahrscheinlichkeitsschätzungen, sondern auch ein Verständnis der eigenen Unsicherheit. Wenn die KI eine Siegwahrscheinlichkeit von 65 Prozent plus/minus fünf Prozentpunkten schätzt, dann liegt der wahre Wert möglicherweise irgendwo zwischen 60 und 70 Prozent. Ein kleiner Unterschied zur Marktquote fällt dann in den Unsicherheitsbereich und signalisiert keinen klaren Value.
Der Expected Value: Das zentrale Konzept für Wettentscheidungen
Jenseits der reinen Wahrscheinlichkeit ist der Expected Value, kurz EV, das entscheidende Konzept für langfristig erfolgreiche Wettstrategien. Der EV gibt an, wie viel Gewinn oder Verlust eine Wette im Durchschnitt über viele Wiederholungen erwarten lässt.
Die Berechnung ist simpel: Man multipliziert die geschätzte Gewinnwahrscheinlichkeit mit dem potentiellen Gewinn und subtrahiert die Verlustwahrscheinlichkeit multipliziert mit dem Einsatz. Wenn die KI 55 Prozent Siegwahrscheinlichkeit schätzt und die Quote 2,0 beträgt, ergibt sich folgender EV: 0,55 mal 1 Euro Gewinn minus 0,45 mal 1 Euro Verlust gleich 0,10 Euro. Pro eingesetztem Euro würde man also langfristig 10 Cent Gewinn erwarten.
Ein positiver EV ist die Voraussetzung für profitables Wetten. Allerdings garantiert er keinen Gewinn im einzelnen Fall. Selbst bei einer Wette mit stark positivem EV kann man verlieren, und das wird in einem signifikanten Anteil der Fälle auch passieren. Der Vorteil zeigt sich erst über viele Wetten hinweg, wenn sich Glück und Pech ausgleichen.
Die Höhe des EV beeinflusst die Einsatzstrategie. Bei einem hohen EV kann ein größerer Einsatz sinnvoll sein, bei einem niedrigen EV sollte der Einsatz entsprechend kleiner ausfallen. Das Kelly-Kriterium, das im nächsten Abschnitt behandelt wird, formalisiert diesen Zusammenhang mathematisch.
Konfidenzintervalle und Unsicherheit: Was KI-Prognosen nicht sagen
Die meisten KI-Tipp-Anbieter präsentieren ihre Wahrscheinlichkeiten als präzise Zahlen. Eine Siegwahrscheinlichkeit von 54,7 Prozent wirkt sehr exakt. Doch diese scheinbare Präzision kann irreführend sein, denn sie verschleiert die inhärente Unsicherheit jeder Prognose.
Jede Schätzung basiert auf einem Modell, und jedes Modell enthält Annahmen. Die Poisson-Verteilung nimmt an, dass Tore unabhängig fallen. Die Stärkeratings nehmen an, dass die historischen Ergebnisse die aktuelle Spielstärke widerspiegeln. Die Gewichtung verschiedener Datenquellen ist eine Modellentscheidung. Jede dieser Annahmen kann mehr oder weniger zutreffen, und die resultierende Unsicherheit pflanzt sich in die Prognose fort.
Ein statistisch korrekter Umgang mit Unsicherheit würde Konfidenzintervalle angeben. Statt 54,7 Prozent Siegwahrscheinlichkeit könnte das System sagen: Die Siegwahrscheinlichkeit liegt mit 95-prozentiger Sicherheit zwischen 48 und 61 Prozent. Eine solche Angabe wäre ehrlicher, aber auch weniger marketingfreundlich.
Die Breite des Konfidenzintervalls hängt von mehreren Faktoren ab. Erstens von der Datenlage: Für ein Spiel zwischen Bayern München und Real Madrid, zwei Teams mit langer Geschichte und vielen analysierten Spielen, sind die Schätzungen tendenziell genauer als für ein Spiel zwischen zwei kleineren Klubs, die selten auf internationalem Niveau aufeinandertreffen.
Zweitens von der Modellkomplexität: Ein einfaches Modell mit wenigen Parametern ist leichter zu schätzen als ein komplexes Modell mit vielen Variablen. Die Unsicherheit über jeden einzelnen Parameter summiert sich zur Gesamtunsicherheit der Prognose.
Drittens von der inhärenten Unvorhersagbarkeit des Fußballs: Selbst mit perfekten Daten und dem besten Modell bleiben Fußballspiele teilweise zufällig. Ein Spieler, der einen genialen Tag erwischt, ein Pfostenschuss, ein Platzverweis – solche Ereignisse sind nicht vollständig prognostizierbar.
Für den praktischen Umgang mit KI-Prognosen bedeutet das: Je größer der Unterschied zwischen der KI-Schätzung und der Marktquote, desto wahrscheinlicher handelt es sich um einen echten Value Bet und nicht um statistisches Rauschen. Kleine Differenzen sollten mit Vorsicht genossen werden, besonders bei Spielen mit unsicherer Datenlage.
Typische Fehler bei der Interpretation von Wahrscheinlichkeiten
Die menschliche Intuition für Wahrscheinlichkeiten ist notorisch unzuverlässig. Psychologen haben zahlreiche kognitive Verzerrungen dokumentiert, die auch beim Umgang mit KI-Sportwetten-Prognosen relevant sind.

Die Überschätzung hoher Wahrscheinlichkeiten ist ein klassischer Fehler. Wenn die KI 75 Prozent Siegwahrscheinlichkeit für Bayern München angibt, fühlt sich das für viele Menschen wie ein sicherer Sieg an. Tatsächlich bedeutet es, dass Bayern in einem von vier Fällen nicht gewinnen würde. Bei einer Serie von Champions-League-Spielen würden selbst solche Favoriten regelmäßig Punkte liegen lassen.
Umgekehrt werden niedrige Wahrscheinlichkeiten oft unterschätzt. Eine Außenseiterchance von 15 Prozent wirkt vernachlässigbar, obwohl sie bedeutet, dass der Außenseiter in etwa jedem siebten Spiel gewinnen würde. Über eine Saison mit vielen Spielen summieren sich diese Überraschungen zu einer signifikanten Zahl.
Der Gambler’s Fallacy ist ein weiterer häufiger Denkfehler. Nach einer Serie von Niederlagen glauben manche, dass nun ein Sieg fällig wäre. Doch Wahrscheinlichkeiten haben kein Gedächtnis. Wenn die KI für ein Spiel 40 Prozent Siegwahrscheinlichkeit angibt, gilt das unabhängig davon, was in den vorherigen Spielen passiert ist. Eine Pechsträhne macht den nächsten Sieg nicht wahrscheinlicher.
Die Verwechslung von Korrelation und Kausalität betrifft die Interpretation von Prognosefaktoren. Wenn die KI feststellt, dass Teams nach einem Trainerwechsel häufiger gewinnen, bedeutet das nicht automatisch, dass der Trainerwechsel die Ursache ist. Möglicherweise wechseln vor allem Teams den Trainer, die sowieso gerade eine Aufwärtsphase durchlaufen. Die Prognose kann trotzdem korrekt sein, aber das Verständnis der Mechanismen erfordert Vorsicht.
Die Verankerung auf Ausgangswerten ist besonders relevant beim Vergleich von KI-Prognosen und eigenen Einschätzungen. Wer zuerst die KI-Wahrscheinlichkeit sieht, passt seine eigene Einschätzung oft unbewusst daran an. Das kann dazu führen, dass Fehler der KI nicht erkannt werden, weil der eigene kritische Verstand bereits beeinflusst ist.
Schließlich gibt es die Tendenz, Bestätigung zu suchen. Wenn eine KI-Prognose zur eigenen Intuition passt, wird sie bereitwillig akzeptiert. Wenn sie widerspricht, wird sie eher angezweifelt. Ein kritischer Umgang mit Prognosen erfordert das Gegenteil: gerade bei übereinstimmenden Prognosen sollte man nach Gegenargumenten suchen, und bei widersprechenden die Argumente der KI ernsthaft prüfen.
Strategien zur Nutzung von Wahrscheinlichkeitsprognosen
Die bloße Kenntnis von Wahrscheinlichkeiten reicht nicht aus, um langfristig erfolgreich zu wetten. Es bedarf einer kohärenten Strategie, die Wahrscheinlichkeiten, Quoten und Risikomanagement integriert.
Das Kelly-Kriterium ist ein mathematisches Werkzeug zur Bestimmung der optimalen Einsatzgröße. Die Formel berücksichtigt sowohl den erwarteten Value einer Wette als auch die eigene Bankroll. Bei einem Value Bet mit hoher Wahrscheinlichkeit und guter Quote empfiehlt Kelly einen höheren Einsatz, bei unsichereren Wetten einen niedrigeren. In der Praxis verwenden viele Wettkunden eine fraktionelle Kelly-Strategie, also nur einen Bruchteil des mathematisch optimalen Einsatzes, um die Volatilität zu reduzieren.
Die Diversifikation über verschiedene Spiele und Wetttypen reduziert das Risiko. Statt alles auf ein einzelnes Champions-League-Spiel zu setzen, verteilen erfahrene Wettkunden ihre Einsätze auf mehrere Begegnungen. Die Wahrscheinlichkeiten einzelner Spiele sind unsicher, aber über viele Spiele gleichen sich Glück und Pech tendenziell aus.
Der Vergleich verschiedener KI-Anbieter kann aufschlussreich sein. Wenn mehrere unabhängige Systeme zu ähnlichen Wahrscheinlichkeitsschätzungen kommen, erhöht das die Konfidenz. Weichen die Schätzungen stark voneinander ab, ist erhöhte Vorsicht geboten. Die Diskrepanz deutet auf Unsicherheit hin, entweder weil die Datenlage unklar ist oder weil die Modelle unterschiedliche Annahmen treffen.
Die Dokumentation der eigenen Wetten ist essentiell für langfristiges Lernen. Wer seine Wetten systematisch aufzeichnet, einschließlich der KI-Wahrscheinlichkeiten und der tatsächlichen Ergebnisse, kann nach einer Weile auswerten, ob die Prognosen kalibriert sind. Wenn die KI regelmäßig 60 Prozent Siegwahrscheinlichkeit angibt und tatsächlich nur 50 Prozent dieser Spiele gewonnen werden, ist das System offenbar zu optimistisch. Solche Erkenntnisse ermöglichen Anpassungen der eigenen Strategie.
Die zeitliche Dimension spielt ebenfalls eine Rolle. Wahrscheinlichkeiten können sich zwischen der Prognoseerstellung und dem Spielbeginn ändern, etwa durch Verletzungsnachrichten oder Aufstellungsbekanntgaben. Wer früh wettet, akzeptiert mehr Unsicherheit, erhält dafür aber möglicherweise bessere Quoten. Wer spät wettet, hat mehr Informationen, aber die Quoten sind oft bereits angepasst.
Wahrscheinlichkeiten als Werkzeug, nicht als Gewissheit
Die abschließende und vielleicht wichtigste Erkenntnis ist, dass Wahrscheinlichkeiten keine Vorhersagen sind. Sie beschreiben nicht, was passieren wird, sondern fassen zusammen, was auf Basis der verfügbaren Informationen am wahrscheinlichsten ist.

Ein Spiel mit 70 Prozent Siegwahrscheinlichkeit für den Favoriten wird in 30 Prozent der Fälle nicht so ausgehen wie erwartet. Das ist keine Fehlfunktion der KI, sondern liegt in der Natur von Wahrscheinlichkeiten. Selbst ein perfektes Prognosemodell würde regelmäßig falsch liegen, weil Fußball eben nicht deterministisch ist.
Diese Einsicht hat praktische Konsequenzen. Wer nach einer verlorenen Wette die KI für einen falschen Tipp verantwortlich macht, hat das Konzept nicht verstanden. Die Qualität einer Prognose zeigt sich nicht am einzelnen Ergebnis, sondern an der langfristigen Kalibrierung. Eine gute KI sollte über viele Spiele hinweg ungefähr so oft richtig liegen, wie ihre Wahrscheinlichkeiten es erwarten lassen.
Für den verantwortungsvollen Umgang mit KI-Sportwetten bedeutet das: Erwartungen realistisch halten, Einsätze dem Risiko anpassen und langfristig denken. Wahrscheinlichkeitsbasierte Prognosen können einen kleinen Vorteil verschaffen, aber sie sind keine Gelddruckmaschine. Der Fußball bleibt unberechenbar, und genau das macht ihn ja interessant.
Die Kalibrierung von KI-Prognosen überprüfen
Ein kritischer Aspekt, den viele Nutzer übersehen, ist die Frage der Kalibrierung. Eine gut kalibrierte KI sollte bei allen Spielen, für die sie 60 Prozent Siegwahrscheinlichkeit vorhersagt, tatsächlich etwa 60 Prozent Siege beobachten. Weicht die tatsächliche Quote systematisch ab, ist das Modell schlecht kalibriert.
Die Überprüfung der Kalibrierung erfordert eine ausreichend große Stichprobe. Bei wenigen Spielen sind zufällige Abweichungen normal und sagen nichts über die Modellqualität aus. Erst nach mehreren hundert Prognosen lassen sich belastbare Aussagen treffen. Für den einzelnen Nutzer ist es daher schwierig, die Kalibrierung selbst zu überprüfen.
Seriöse Anbieter von KI-Tipps veröffentlichen ihre historischen Trefferquoten und ermöglichen so eine externe Überprüfung. Anbieter, die diese Transparenz verweigern, sollten kritisch betrachtet werden. Die Behauptung hoher Trefferquoten ohne Nachweise ist ein Warnsignal.
Die Brier-Score ist eine gängige Metrik zur Bewertung der Kalibrierung. Sie misst die quadrierte Abweichung zwischen der vorhergesagten Wahrscheinlichkeit und dem tatsächlichen Ergebnis. Ein niedrigerer Brier-Score bedeutet bessere Kalibrierung. Professionelle Nutzer achten auf diese Kennzahl, wenn sie verschiedene KI-Anbieter vergleichen.
Die Champions League bietet mit ihrer Mischung aus Weltklasseteams und unvorhersehbaren Momenten das perfekte Umfeld für wahrscheinlichkeitsbasierte Analysen. Die KI kann helfen, die Chancen einzuordnen und fundierte Entscheidungen zu treffen. Aber sie kann das Spiel nicht berechnen, weil Fußball zum Glück mehr ist als Mathematik.