
Sportvorhersagen
Ladevorgang...
Ladevorgang...
Es gibt einen fundamentalen Unterschied zwischen der Frage, wer das nächste Spiel gewinnt, und der Frage, wer am Ende einer ganzen Saison den Pokal in den Himmel recken wird. Während die erste Frage in neunzig Minuten beantwortet ist, erstreckt sich die zweite über Monate, dutzende Spiele und unzählige Wendungen. Für KI-Systeme, die normalerweise auf kurzfristige Prognosen spezialisiert sind, stellt diese Langzeitperspektive eine besondere Herausforderung dar.
Die Champions-League-Saison 2025/26 steht vor der Tür, und wieder einmal werden Millionen von Fußballfans versuchen, den zukünftigen Sieger zu erraten. Die Buchmacher haben ihre Quoten längst aufgestellt, und auch die KI-gestützten Analyseplattformen liefern ihre ersten Einschätzungen. Doch was taugen diese Langzeitprognosen wirklich? Kann ein Algorithmus im August vorhersagen, was im Mai passiert? Und wenn ja, wie macht er das?
Dieser Artikel widmet sich den spezifischen Anforderungen und Methoden von Langzeit-KI-Prognosen für die Champions League. Er erklärt, worin sich saisonübergreifende Vorhersagen von Match-Prognosen unterscheiden, welche Faktoren für Langzeitwetten relevant sind und wie man als Nutzer mit der inhärenten Unsicherheit solcher Prognosen umgehen sollte. Dabei werden wir auch die Frage stellen, ob und wann Langzeitwetten überhaupt sinnvoll sein können. Saison-Strategie bei KI Champions League Tipps.
Die grundlegende Herausforderung: Vorhersagen über Monate hinweg
Wenn ein KI-System eine Prognose für ein Spiel erstellt, das in wenigen Stunden angepfiffen wird, kann es auf relativ stabile Informationen zurückgreifen. Die Kader sind weitgehend bekannt, die Form der letzten Wochen lässt sich quantifizieren, und selbst Unsicherheitsfaktoren wie das Wetter lassen sich einigermaßen verlässlich einschätzen. Je kürzer der Zeithorizont, desto präziser kann die Prognose sein. Lesen Sie auch Logik statt Zufall.
Bei Langzeitprognosen kehrt sich dieses Verhältnis um. Im August weiß niemand, welche Spieler im Februar verletzt sein werden, welche Trainer entlassen und welche Neuzugänge sich als Volltreffer oder Fehleinkauf erweisen werden. Die Parameter, die für die Saison entscheidend sein könnten, sind zum Zeitpunkt der Prognose noch gar nicht bekannt. Das Modell muss also nicht nur den aktuellen Zustand analysieren, sondern auch vorhersagen, wie sich dieser Zustand über viele Monate entwickeln wird.
Diese doppelte Ungewissheit macht Langzeitprognosen grundsätzlich unsicherer als Kurzfristprognosen. Das ist keine Schwäche spezifischer Modelle, sondern eine mathematische Notwendigkeit. Jede zusätzliche Variable, jeder zusätzliche Zeitschritt erhöht die Streuung der möglichen Ergebnisse. Ein System, das für Einzelspiele Trefferquoten von 55 Prozent erreicht, kann bei Saisonprognosen weit darunter liegen, ohne dass dies auf einen Fehler im Modell hindeuten würde.
Die praktische Konsequenz ist, dass Langzeitprognosen anders interpretiert werden müssen als Kurzfristprognosen. Eine Aussage wie Real Madrid hat 15 Prozent Wahrscheinlichkeit, die Champions League zu gewinnen bedeutet nicht, dass das Ergebnis sicher ist, wenn die Wahrscheinlichkeit hoch genug wäre. Sie bedeutet, dass von hundert simulierten Saisonen etwa fünfzehn mit einem Triumph der Königlichen enden würden. Die anderen fünfundachtzig enden anders, und selbst das favorisierte Team kann in der realen Welt scheitern.
Welche Märkte KI-Systeme für Langzeitwetten analysieren
Der Begriff Langzeitwetten umfasst verschiedene Wettmärkte, die sich in ihrer Komplexität und Prognostizierbarkeit unterscheiden. Am bekanntesten ist natürlich die Wette auf den Turniersieger. Wer wird am Ende die Champions League gewinnen? Diese Frage ist die schwierigste, weil sie nicht nur fordert, dass ein Team stark ist, sondern auch, dass es in entscheidenden Momenten die richtigen Ergebnisse erzielt.
Etwas einfacher zu prognostizieren sind die Finalteilnehmer. Hier genügt es, dass ein Team unter die letzten beiden kommt, unabhängig vom Ausgang des Finals. Die Ungewissheit ist geringer, weil mehr Teams die Bedingung erfüllen können und weil eine Niederlage im Finale nicht zum Scheitern der Prognose führt.
Noch eine Stufe darunter liegt das Erreichen des Halbfinales oder des Viertelfinales. Je weiter man in der Pyramide nach unten geht, desto mehr Teams erfüllen die Bedingung und desto höher ist die Prognosesicherheit. Die Kehrseite ist, dass auch die Quoten entsprechend niedriger ausfallen. Eine Wette darauf, dass Real Madrid das Viertelfinale erreicht, mag eine hohe Erfolgswahrscheinlichkeit haben, aber die angebotene Quote wird diese Wahrscheinlichkeit widerspiegeln.
Ein spezieller Markt, der seit der Einführung der Ligaphase an Bedeutung gewonnen hat, ist das Erreichen der K.o.-Runde. Die Frage lautet: Welches Team schafft es unter die besten vierundzwanzig? Für Außenseiter kann dies ein realistisches Ziel sein, und KI-Systeme können analysieren, welche Underdogs bessere Chancen haben als die Quoten suggerieren.
Schließlich gibt es noch Team-spezifische Märkte wie die Anzahl der Tore oder Punkte in der Ligaphase, Gruppensieger-Prognosen oder Head-to-Head-Vergleiche zwischen bestimmten Teams. Diese Märkte sind weniger komplex als der Gesamtsieg, bieten aber manchmal interessante Value-Gelegenheiten, wenn das KI-Modell zu anderen Einschätzungen kommt als der Markt.
Die Datenbasis für saisonübergreifende Prognosen
Langzeitprognosen erfordern eine andere Datenbasis als Kurzfristprognosen. Während für ein Einzelspiel vor allem die aktuelle Form und die direkten Vergleiche relevant sind, müssen Saisonprognosen auf stabilere, langfristig aussagekräftige Metriken zurückgreifen.
Ein zentraler Faktor ist die Kaderqualität. Sie lässt sich auf verschiedene Weisen quantifizieren: über den Marktwert der Spieler, über individuelle Leistungsdaten wie Expected Goals oder über aggregierte Teamstatistiken aus der Vorsaison. Ein tieferer Kader mit vielen hochwertigen Alternativen erhöht die Wahrscheinlichkeit, Verletzungen und Sperren zu kompensieren, was über eine lange Saison entscheidend sein kann.
Ein weiterer Faktor ist die historische Performance im Wettbewerb selbst. Einige Vereine haben eine nachgewiesene Erfolgsgeschichte in der Champions League, während andere regelmäßig in entscheidenden Momenten scheitern. Diese Muster können auf institutionelle Stärken oder Schwächen hindeuten, die sich nicht vollständig in aktuellen Leistungsdaten widerspiegeln. KI-Systeme können solche historischen Trends identifizieren und gewichten.
Die Trainerqualität ist ein Faktor, der sich schwerer quantifizieren lässt, aber dennoch relevant ist. Trainer mit nachgewiesener Erfahrung in K.o.-Spielen und mit einer Erfolgsbilanz in europäischen Wettbewerben können einen Unterschied machen, der über die reine Summe der Spielerqualität hinausgeht. Einige Modelle versuchen, diesen Faktor über Proxy-Variablen wie vergangene Ergebnisse oder taktische Flexibilität zu erfassen.
Weniger greifbar, aber nicht weniger wichtig ist die Frage der Belastungssteuerung. Teams, die in ihrer Liga um den Titel kämpfen, in Pokalwettbewerben weit kommen und internationale Verpflichtungen haben, stehen vor Kapazitätsproblemen. Die Fähigkeit eines Vereins, mit Mehrfachbelastung umzugehen, wird über eine ganze Saison relevant. Hier fließen Daten zur Kadertiefe, zur Rotationspraxis des Trainers und zur Spielplananalyse ein.
Wie KI-Systeme Langzeitprognosen erstellen
Die technischen Methoden für Langzeitprognosen unterscheiden sich von denen für Kurzfristprognosen, auch wenn es Überschneidungen gibt. Der grundlegende Ansatz besteht darin, den gesamten Turnierverlauf zu simulieren, nicht nur einzelne Spiele.
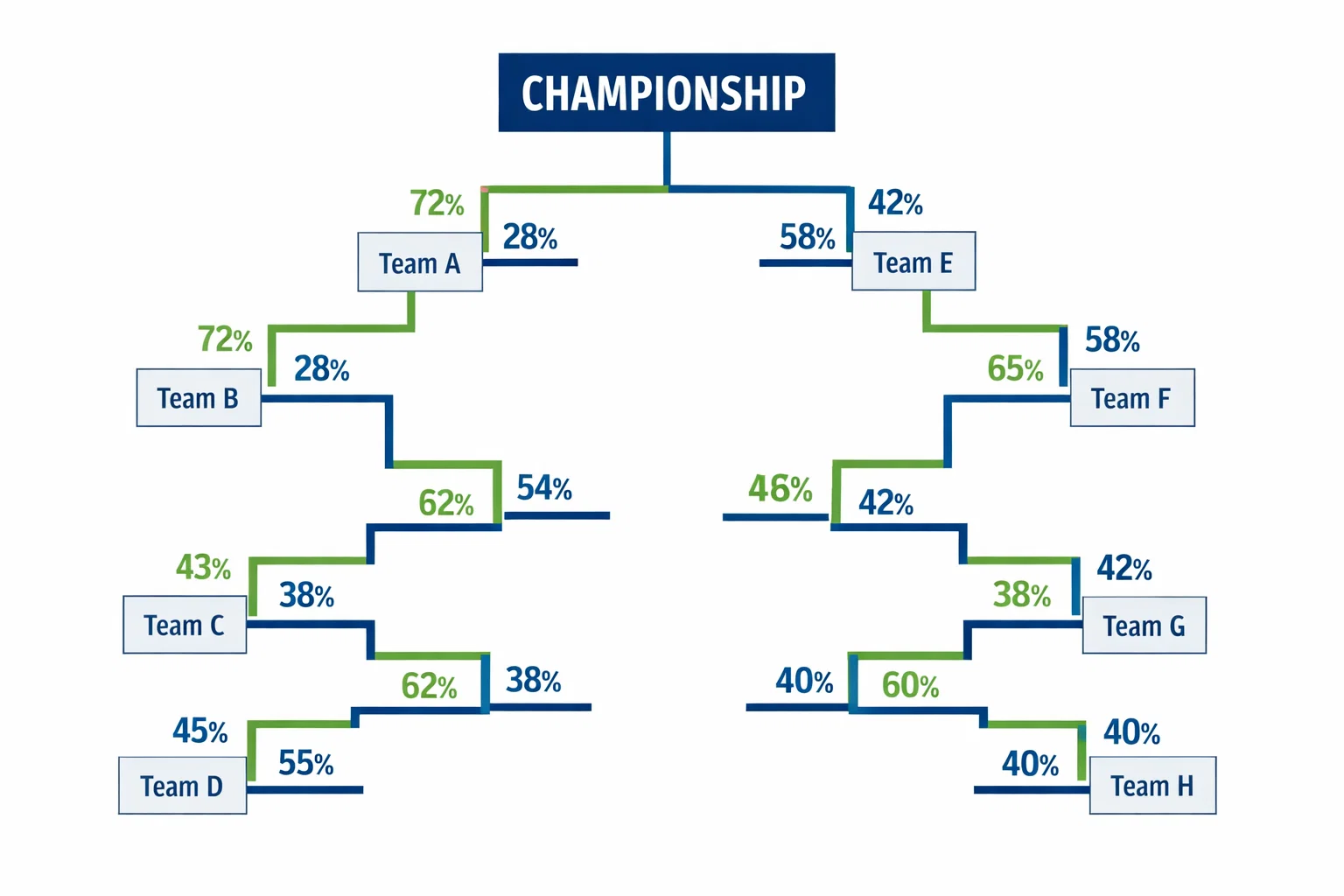
Monte-Carlo-Simulationen sind hier das Mittel der Wahl. Das System generiert tausende virtuelle Turnierverläufe, von der Ligaphase bis zum Finale. Für jede Partie innerhalb dieser Simulation wird eine Ergebnisprognose erstellt, basierend auf den zugrunde liegenden Modellparametern. Am Ende jeder Simulation steht ein virtueller Turniersieger, und die Häufigkeit, mit der ein Team in diesen Simulationen gewinnt, entspricht seiner geschätzten Siegwahrscheinlichkeit.
Die Qualität dieser Simulationen hängt von mehreren Faktoren ab. Erstens müssen die zugrunde liegenden Match-Prognosen vernünftig kalibriert sein. Wenn das Modell systematisch die Stärke bestimmter Teams über- oder unterschätzt, pflanzt sich dieser Fehler durch alle Simulationen fort. Zweitens müssen die Korrelationen zwischen verschiedenen Spielen berücksichtigt werden. Ein Team, das am ersten Spieltag schlecht spielt, tut dies möglicherweise auch am zweiten, wenn die Ursache in einem systematischen Problem liegt.
Fortschrittlichere Modelle versuchen, auch dynamische Entwicklungen während der Saison zu berücksichtigen. Sie modellieren die Wahrscheinlichkeit von Verletzungen, Trainerwechseln oder Formeinbrüchen und integrieren diese Unsicherheiten in ihre Simulationen. Das erhöht die Komplexität des Modells erheblich, kann aber zu realistischeren Streubreiten führen.
Ein kritischer Punkt bei allen Langzeitsimulationen ist die Kalibrierung der Unsicherheit. Ein Modell, das zu selbstbewusst ist, wird die tatsächliche Varianz unterschätzen und zu präzise Prognosen liefern. Ein Modell, das zu unsicher ist, wird Prognosen liefern, die kaum mehr aussagen als der Zufall. Die richtige Balance zu finden, erfordert sorgfältige Validierung anhand historischer Daten.
Faktoren, die für Langzeitprognosen besonders relevant sind
Einige Faktoren, die für Einzelspiele nur eine geringe Rolle spielen, werden über eine ganze Saison entscheidend. Die Fähigkeit eines Kaders, eine lange Saison durchzustehen, gehört dazu. Ein Team mit zwanzig hochwertigen Feldspielern hat einen strukturellen Vorteil gegenüber einem Team, dessen Qualität nach der Startelf stark abfällt.
Die Verletzungsanfälligkeit ist ein verwandter Faktor. Historische Daten zeigen, dass manche Spieler und manche Teams überproportional oft von Verletzungen betroffen sind. Das kann an der Spielweise liegen, am medizinischen Stab oder schlicht an Pech. Für Langzeitprognosen ist es sinnvoll, diese Muster zu berücksichtigen und Teams mit chronischen Verletzungsproblemen entsprechend abzuwerten.
Die Trainererfahrung auf internationaler Bühne ist ein weiterer Faktor. Trainer, die noch nie eine Mannschaft durch eine Champions-League-Saison geführt haben, müssen lernen und Fehler machen. Trainer mit nachgewiesener Erfahrung in K.o.-Spielen haben oft einen Vorteil in den entscheidenden Momenten, wenn taktische Anpassungen und Nerven den Ausschlag geben.
Die Auslosung spielt ebenfalls eine Rolle, auch wenn sie zum Zeitpunkt der frühen Saisonprognosen noch nicht feststeht. Im neuen Ligaphase-Format werden die Gegner vor Saisonbeginn ausgelost. Ein Team, das durch die Auslosung einen relativ leichten Weg erwischt hat, wird eher unter die ersten acht kommen als ein Team mit schwierigen Gegnern. KI-Systeme können nach der Auslosung ihre Prognosen entsprechend anpassen.
Schließlich ist die Motivation ein schwer greifbarer, aber relevanter Faktor. Ein Team, das in der Liga chancenlos auf den Titel ist, könnte sich auf die Champions League konzentrieren. Ein Team, das um mehrere Trophäen kämpft, könnte Ressourcen aufteilen müssen. Diese strategischen Überlegungen lassen sich nur bedingt quantifizieren, sollten aber bei der Interpretation von KI-Prognosen bedacht werden.
Die besonderen Herausforderungen der Saison 2025/26
Jede Saison bringt ihre eigenen Besonderheiten mit, die in Langzeitprognosen einfließen müssen. Für die Saison 2025/26 gibt es mehrere Faktoren, die besondere Aufmerksamkeit verdienen.
Das neue Ligaphase-Format, das seit 2024/25 in Kraft ist, hat das Turnier grundlegend verändert. Die ersten Erfahrungswerte aus der Vorsaison zeigen, wie Teams mit dem neuen Modus umgehen. Einige Vereine haben sich schnell angepasst, andere taten sich schwer. Diese Anpassungsfähigkeit ist ein Datenpunkt, der in Prognosen für die Folgesaison einfließen kann.
Die FIFA-Klub-Weltmeisterschaft, die im Sommer 2025 in den USA stattfindet, beeinflusst die Saisonvorbereitung vieler europäischer Topclubs. Teams, die an diesem Turnier teilnehmen, haben eine verkürzte Erholungsphase und möglicherweise Ermüdungseffekte zu Saisonbeginn. Dieser Faktor ist für Langzeitprognosen relevant, weil frühe Rückstände in der Ligaphase den gesamten Saisonverlauf beeinflussen können.
Transferperioden bringen Unsicherheit in jede Saisonprognose. Große Transfers können die Kräfteverhältnisse verschieben, und zum Zeitpunkt früher Prognosen ist oft noch unklar, welche Deals zustande kommen werden. KI-Systeme können mit verschiedenen Szenarien arbeiten und ihre Prognosen anpassen, sobald der Transfermarkt geschlossen ist.
Die nationale Ligabelastung variiert von Saison zu Saison. In Jahren, in denen die großen Ligen besonders umkämpft sind, könnte die Konzentration auf die Champions League leiden. Umgekehrt könnten Teams, die in der Liga frühzeitig abgeschlagen sind, ihre Kräfte auf den internationalen Wettbewerb fokussieren. Diese Dynamiken lassen sich zu Saisonbeginn nur bedingt vorhersagen.
Vergleich: KI-Prognosen und Buchmacher-Quoten
Die Buchmacher sind die ursprünglichen Langzeitprognostiker. Ihre Quoten für den Champions-League-Sieger werden bereits Monate vor Saisonbeginn angeboten und spiegeln die aggregierte Markteinschätzung wider. Ein Vergleich zwischen KI-Prognosen und Buchmacher-Quoten kann aufschlussreich sein.
Zunächst zur Umrechnung: Eine Quote von 5.00 impliziert eine Wahrscheinlichkeit von 20 Prozent, wenn man die Buchmachermarge ignoriert. In Wirklichkeit ist die implizite Wahrscheinlichkeit niedriger, weil die Marge eingepreist ist. Bei Langzeitwetten sind die Margen typischerweise höher als bei Einzelspielen, weil das gebundene Kapital über einen längeren Zeitraum verzinst werden muss.
KI-Prognosen liefern hingegen explizite Wahrscheinlichkeiten ohne eingepreiste Marge. Ein direkter Vergleich ist daher nicht trivial, aber möglich. Wenn das KI-Modell für ein Team eine höhere Siegwahrscheinlichkeit berechnet, als die Quote impliziert, könnte das auf Value hindeuten. Wenn die KI-Wahrscheinlichkeit niedriger ist, sollte man die Finger von dieser Wette lassen.
In der Praxis zeigen Studien, dass die Buchmacher-Quoten für Langzeitwetten erstaunlich gut kalibriert sind. Der Markt aggregiert die Einschätzungen vieler Experten und passt sich kontinuierlich an neue Informationen an. KI-Modelle können in Einzelfällen dennoch systematische Diskrepanzen aufdecken, etwa wenn bestimmte Faktoren vom Markt unter- oder überbewertet werden.
Ein typisches Muster ist die Überbewertung bekannter Namen. Teams mit großer Tradition und vielen Fans ziehen überproportional viele Wetten an, was die Quoten drückt und den Value reduziert. KI-Systeme sind gegen diesen Popularitätsbias immun und können Teams identifizieren, deren Stärke vom Markt unterschätzt wird.
Umgekehrt gibt es den Recency-Bias, die Überbewertung jüngster Ereignisse. Ein Team, das gerade die Champions League gewonnen hat, wird im Folgejahr oft zu stark eingeschätzt, obwohl der Erfolg teilweise auf Glück und günstigen Umständen beruhte. KI-Modelle können zwischen Kompetenz und Glück unterscheiden und entsprechend adjustieren.

Strategien für das Timing von Saisonwetten
Der Zeitpunkt einer Langzeitwette beeinflusst deren Erfolgsaussichten. Die Quoten verändern sich über die Saison, und kluge Wetter können diese Dynamik zu ihrem Vorteil nutzen.
Sehr frühe Wetten, also vor Saisonbeginn oder sogar vor Ende der Transferperiode, bieten die höchste Unsicherheit, aber auch die größten Quotenschwankungen. Wenn das eigene Modell zu einer deutlich anderen Einschätzung kommt als der frühe Markt, kann hier der größte Value liegen. Das Risiko besteht darin, dass wichtige Informationen noch fehlen, etwa finale Kaderentscheidungen oder Auslosungsergebnisse.
Wetten nach Saisonbeginn profitieren von ersten Leistungsdaten, die frühe Einschätzungen bestätigen oder widerlegen können. Ein Team, das überraschend stark startet, wird aufgewertet, seine Quote sinkt. Wer an dieses Team geglaubt hat, bevor der Rest des Marktes es erkannte, profitiert von besseren Quoten. Umgekehrt werden Teams, die enttäuschen, abgewertet, und Wetten auf sie bieten plötzlich Value, wenn das Modell die Schwäche als vorübergehend einschätzt.
Midsaison-Wetten sind interessant, wenn sich die Kräfteverhältnisse verschoben haben. Ein Team, das durch Verletzungen zurückgefallen ist, wird niedrig bewertet, obwohl die Spieler zur entscheidenden Phase zurückkehren könnten. Ein Team, das überperformt hat, wird hoch bewertet, obwohl die Daten auf Regression zur Mitte hindeuten. KI-Systeme können diese Überreaktionen des Marktes identifizieren.
Die generelle Empfehlung lautet, Langzeitwetten nicht als einmalige Aktion zu betrachten, sondern als Prozess. Die Informationslage ändert sich über die Saison, und damit sollte sich auch die eigene Positionierung ändern. Wer zu Saisonbeginn auf ein Team gesetzt hat und im Verlauf neue Erkenntnisse gewinnt, sollte bereit sein, die Position anzupassen, sei es durch zusätzliche Wetten oder durch Hedging.
Die Rolle der Unsicherheit: Konfidenzintervalle verstehen
Langzeitprognosen ohne Angabe ihrer Unsicherheit sind weitgehend wertlos. Die Aussage Manchester City gewinnt die Champions League mit 18 Prozent Wahrscheinlichkeit klingt präzise, aber die eigentliche Frage ist, wie sicher man sich dieser Zahl sein kann.
Konfidenzintervalle sind ein Werkzeug, um diese Unsicherheit zu kommunizieren. Statt einer Punktprognose liefern sie einen Bereich. Eine Aussage wie Die Siegwahrscheinlichkeit von Manchester City liegt zwischen 12 und 24 Prozent mit 90 Prozent Konfidenz ist informativer als eine einzelne Zahl, weil sie die Streubreite der möglichen Einschätzungen zeigt.
Für Langzeitprognosen sind diese Konfidenzintervalle typischerweise breiter als für Kurzfristprognosen. Das liegt an der größeren Unsicherheit über zukünftige Entwicklungen. Ein Modell, das enge Konfidenzintervalle für Saisonprognosen liefert, ist entweder sehr selbstbewusst oder nicht richtig kalibriert. In den meisten Fällen sollte man Letzteres vermuten.
Die praktische Nutzung von Konfidenzintervallen besteht darin, sie mit den Buchmacher-Quoten zu vergleichen. Wenn die implizite Wahrscheinlichkeit der Quote außerhalb des Konfidenzintervalls liegt, könnte das auf Value hindeuten. Wenn sie innerhalb des Intervalls liegt, ist die Einschätzung des Modells mit der Marktmeinung kompatibel, und es gibt keinen klaren Anhaltspunkt für eine Wette.
Eine fortgeschrittene Anwendung ist die Szenarioanalyse. Statt eine einzelne Prognose zu akzeptieren, fragt man: Unter welchen Bedingungen wäre meine Prognose deutlich anders? Wenn das Ergebnis stark davon abhängt, ob ein bestimmter Spieler fit bleibt oder ob ein bestimmter Trainer entlassen wird, sollte man diese Szenarien explizit modellieren und ihre Wahrscheinlichkeiten einschätzen.
Historische Genauigkeit von Langzeitprognosen
Wie gut waren KI-Langzeitprognosen in der Vergangenheit? Die ehrliche Antwort lautet: mäßig, aber das liegt in der Natur der Sache.
Retrospektive Analysen zeigen, dass die Favoriten in der Champions League häufiger scheitern als in nationalen Ligen. Das liegt an der K.o.-Struktur des Wettbewerbs, in der einzelne Spiele oder sogar einzelne Momente über Weiterkommen und Ausscheiden entscheiden. Ein Team kann über eine Liga-Saison die beste Mannschaft sein und dennoch in einem Viertelfinale ausscheiden, weil der Torwart zwei entscheidende Fehler macht.
Statistiken aus vergangenen Saisons illustrieren dieses Phänomen. Der vorhergesagte Favorit gewann die Champions League in den letzten zwei Jahrzehnten nur in etwa einem Drittel der Fälle. Das bedeutet nicht, dass die Prognosen falsch waren. Wenn ein Team mit 20 Prozent Wahrscheinlichkeit gewinnt, wird es in fünf Saisons einmal triumphieren und viermal scheitern. Das viermalige Scheitern beweist nicht, dass die 20 Prozent zu hoch angesetzt waren.
Die richtige Bewertung von Langzeitprognosen erfolgt über viele Saisons hinweg. Man sammelt die Prognosen, vergleicht sie mit den tatsächlichen Ergebnissen und prüft, ob die vorhergesagten Wahrscheinlichkeiten mit den realisierten Häufigkeiten übereinstimmen. Ein gut kalibriertes Modell sollte in etwa so oft richtig liegen, wie seine eigenen Wahrscheinlichkeiten vorhersagen.
Für den einzelnen Nutzer ist diese langfristige Perspektive oft unbefriedigend. Man möchte wissen, ob die aktuelle Prognose stimmt, nicht ob das Modell über zehn Jahre korrekt kalibriert ist. Diese Spannung zwischen statistischer Validität und praktischem Nutzen ist inhärent und lässt sich nicht auflösen. Die einzige ehrliche Antwort auf die Frage, ob eine Langzeitprognose richtig ist, lautet: Das werden wir am Ende der Saison wissen.
Value-Opportunities bei Langzeitwetten
Trotz der hohen Unsicherheit können Langzeitwetten unter bestimmten Bedingungen Value bieten. Die Kunst besteht darin, diese Gelegenheiten zu identifizieren und von Situationen zu unterscheiden, in denen der Markt recht hat.
Eine typische Value-Opportunity entsteht, wenn ein Team strukturell unterschätzt wird. Das kann passieren, wenn der Markt auf jüngste Enttäuschungen überreagiert. Ein Verein, der in der Vorsaison früh ausgeschieden ist, wird oft stärker abgewertet, als es seine fundamentale Stärke rechtfertigt. Wenn das KI-Modell zeigt, dass das Ausscheiden auf Pech oder spezifische Umstände zurückzuführen war, könnte die niedrige Quote Value bieten.
Eine weitere Quelle von Value sind Kaderveränderungen, die der Markt noch nicht vollständig eingepreist hat. Ein Team, das einen entscheidenden Spielmacher verpflichtet hat, wird möglicherweise erst im Saisonverlauf aufgewertet, wenn die Wirkung sichtbar wird. Wer die Verstärkung früh erkennt und ihre Auswirkungen korrekt einschätzt, kann von besseren Quoten profitieren.
Auch strukturelle Faktoren können Value erzeugen. Teams mit einem besonders tiefen Kader werden in frühen Saisonphasen oft unterschätzt, weil die Breite der Optionen noch nicht relevant ist. Über eine lange Saison mit vielen Spielen und unvermeidlichen Verletzungen wird diese Kadertiefe zum Vorteil. KI-Modelle, die diesen Faktor explizit berücksichtigen, können entsprechende Value-Situationen identifizieren.
Die Kehrseite ist, dass Value bei Langzeitwetten auch Illusion sein kann. Der Markt ist nicht dumm, und offensichtliche Muster sind meist bereits eingepreist. Wer glaubt, eine Value-Bet gefunden zu haben, sollte sich fragen, warum der Rest des Marktes diese Gelegenheit übersehen hat. Wenn die Antwort nicht überzeugend ist, sollte man skeptisch bleiben.
Risikomanagement bei Langzeitwetten
Langzeitwetten unterscheiden sich von Kurzfristwetten nicht nur in ihrer Prognoseunsicherheit, sondern auch in ihrem Risikoprofil. Das hat Konsequenzen für das Kapitalmanagement.
Das offensichtlichste Merkmal ist die Kapitalbindung. Geld, das für eine Langzeitwette eingesetzt wird, ist über Monate blockiert. Es kann nicht für andere Wetten verwendet werden, und es gibt keine Möglichkeit, vorzeitig auszusteigen, wenn sich die Einschätzung ändert. Diese Opportunitätskosten sollten in die Entscheidung einbezogen werden.
Einige Buchmacher bieten mittlerweile Cashout-Optionen für Langzeitwetten an. Dabei kann man die Wette vorzeitig auflösen und erhält einen Teil des potentiellen Gewinns oder reduziert den Verlust. Die angebotenen Cashout-Werte reflektieren die aktuellen Wahrscheinlichkeiten und beinhalten natürlich eine Marge des Buchmachers. Ob ein Cashout sinnvoll ist, hängt von der individuellen Situation und der eigenen Einschätzung ab.
Die Empfehlung für die Einsatzhöhe bei Langzeitwetten ist tendenziell konservativer als bei Kurzfristwetten. Die höhere Unsicherheit rechtfertigt kleinere Einsätze relativ zur Bankroll. Das Kelly-Kriterium, das den optimalen Einsatz basierend auf Vorteil und Quote berechnet, liefert bei Langzeitwetten typischerweise niedrigere Werte, weil die Prognosequalität geringer ist.
Ein verbreiteter Fehler ist die Akkumulation von Langzeitwetten ohne Gesamtbetrachtung. Wer zu Saisonbeginn auf fünf verschiedene Teams als mögliche Champions-League-Sieger setzt, hat garantiert vier Verlierer. Die Gesamtrendite dieser Strategie hängt von den Quoten und Einsätzen ab und ist oft negativ, weil die Buchmachermarge mehrfach zu Buche schlägt. Ein durchdachtes Portfolio statt wilder Streuung ist die bessere Strategie.

Die psychologische Dimension: Geduld als Schlüsselkompetenz
Langzeitwetten erfordern Geduld, und Geduld ist eine Ressource, die vielen Wettern fehlt. Die Monate zwischen Wettplatzierung und Ergebnis sind eine psychologische Belastung, die nicht unterschätzt werden sollte.
Das Problem beginnt mit der verzögerten Rückmeldung. Bei einer Einzelspielwette weiß man nach neunzig Minuten, ob man richtig lag. Bei einer Langzeitwette wartet man Monate, und in dieser Zeit passieren viele Dinge, die die Einschätzung beeinflussen können. Jede Niederlage des gewählten Teams löst Zweifel aus, jeder Sieg bestärkt, obwohl beide Informationen für das Endergebnis möglicherweise irrelevant sind.
Ein verwandtes Problem ist die nachträgliche Rationalisierung. Wenn das gewählte Team früh ausscheidet, neigt man dazu, Gründe zu finden, warum die Prognose trotzdem richtig war. Es war Pech, der Schiedsrichter war schlecht, die Verletzung des Schlüsselspielers war nicht vorhersehbar. Diese Rationalisierungen mögen teilweise zutreffen, verhindern aber das Lernen aus Fehlern.
Die Empfehlung lautet, die eigene Entscheidungslogik zu dokumentieren, bevor das Ergebnis bekannt ist. Warum wurde diese Wette platziert? Welche Annahmen liegen zugrunde? Unter welchen Bedingungen würde man die Einschätzung revidieren? Diese Dokumentation ermöglicht später eine ehrliche Bewertung, ob die Entscheidung zum Zeitpunkt der Platzierung vernünftig war, unabhängig vom zufallsbehafteten Ergebnis.
Ein weiterer psychologischer Faktor ist der Umgang mit Early Value. Wenn man früh in der Saison auf ein Team gesetzt hat und dieses Team startet schlecht, sinkt die Wahrscheinlichkeit eines Gewinns, aber das gebundene Kapital ist verloren. Die Versuchung ist groß, durch weitere Wetten nachzujustieren, was oft zu irrationalem Verhalten führt. Ein klarer Plan vor Saisonbeginn, der solche Szenarien berücksichtigt, ist die beste Verteidigung.
Die Grenzen der KI bei Langzeitprognosen
Bei aller Nützlichkeit von KI-gestützten Analysen sollte man ihre Grenzen kennen. Langzeitprognosen sind strukturell unsicherer als Kurzfristprognosen, und kein Algorithmus kann diese fundamentale Unsicherheit eliminieren.
Die erste Grenze betrifft unvorhersehbare Ereignisse. Verletzungen von Schlüsselspielern, Trainerwechsel, Skandale, sogar externe Faktoren wie Pandemien oder geopolitische Krisen können Saisonverläufe völlig verändern. KI-Modelle können die Wahrscheinlichkeit solcher Ereignisse einschätzen und ihre Auswirkungen modellieren, aber sie können nicht vorhersagen, wann und wo sie eintreten werden.
Die zweite Grenze liegt in der Komplexität menschlicher Faktoren. Die Teamchemie, die Motivation in entscheidenden Momenten, die Nervenstärke unter Druck, all das beeinflusst die Ergebnisse, lässt sich aber nur schwer quantifizieren. KI-Systeme arbeiten mit Daten, und Daten erfassen nur einen Teil dessen, was auf dem Spielfeld und in der Kabine passiert.
Die dritte Grenze ist die Reflexivität des Marktes. Wenn viele Marktteilnehmer ähnliche KI-Modelle nutzen, werden deren Erkenntnisse in die Quoten eingepreist. Der Informationsvorsprung, den ein gutes Modell theoretisch bieten könnte, verschwindet, wenn alle denselben Vorteil zu nutzen versuchen. Der Wettmarkt wird effizienter, und die Möglichkeiten für systematische Überrenditen schrumpfen.
Die praktische Konsequenz ist Bescheidenheit. KI-Langzeitprognosen sind nützliche Werkzeuge zur Strukturierung der eigenen Analyse und zur Identifikation möglicher Value-Situationen. Sie sind keine Kristallkugeln, die die Zukunft vorhersagen können. Wer sie mit dieser realistischen Erwartung nutzt, wird weder enttäuscht noch in die Irre geführt.
Praktische Empfehlungen für die Saison 2025/26
Nach all der Theorie stellt sich die praktische Frage: Wie sollte man KI-Langzeitprognosen für die kommende Champions-League-Saison nutzen?
Der erste Schritt ist die Auswahl eines vertrauenswürdigen Prognoseanbieters. Kriterien sind Transparenz der Methodik, nachgewiesene historische Performance und angemessene Kommunikation von Unsicherheit. Anbieter, die hohe Trefferquoten versprechen oder ihre Methoden nicht offenlegen, sollten skeptisch betrachtet werden.
Der zweite Schritt ist die eigene Recherche. KI-Prognosen sind Informationen, keine Handlungsanweisungen. Sie sollten mit anderen Quellen abgeglichen werden: mit der eigenen Einschätzung, mit Expertenanalysen, mit den Buchmacher-Quoten. Diskrepanzen zwischen verschiedenen Quellen sind interessant und verdienen weitere Untersuchung.
Der dritte Schritt ist die Portfoliobildung. Statt alle Eier in einen Korb zu legen, kann man verschiedene Wetten kombinieren, die unterschiedliche Szenarien abdecken. Eine Wette auf den Favoriten, eine auf einen unterschätzten Außenseiter, eine auf das Erreichen der K.o.-Runde durch ein bestimmtes Team. Die Kombination reduziert das Gesamtrisiko und erhöht die Wahrscheinlichkeit, dass zumindest einige Wetten aufgehen.
Der vierte Schritt ist die Anpassung über die Saison. Die Informationslage ändert sich, und damit sollten sich auch die eigenen Einschätzungen ändern. Wer zu Saisonbeginn eine Position bezogen hat, sollte bereit sein, diese Position im Lichte neuer Erkenntnisse zu überdenken. Stur an einer Einschätzung festzuhalten, obwohl die Daten dagegen sprechen, ist keine Konsequenz, sondern Starrsinn.
Der fünfte und wichtigste Schritt ist die Akzeptanz von Unsicherheit. Langzeitwetten sind Wetten, keine Investitionen mit garantierter Rendite. Man kann alles richtig machen und trotzdem verlieren, weil der Zufall anders entschieden hat. Wer diese Grundrealität akzeptiert, kann Langzeitwetten als das genießen, was sie sind: eine interessante Ergänzung zur Saison, die Spiele spannender macht und im besten Fall mit einem Gewinn belohnt wird.
Ausblick: Die Zukunft von KI-Langzeitprognosen
Die Technologie entwickelt sich weiter, und mit ihr die Qualität von Langzeitprognosen. Einige Trends zeichnen sich ab, die für künftige Saisons relevant werden könnten.
Verbesserte Datenerfassung durch Tracking-Systeme und Computer Vision ermöglicht detailliertere Spieleranalysen. Statt aggregierter Teamstatistiken könnten künftige Modelle individuelle Spielerleistungen in feiner Auflösung berücksichtigen und so präzisere Einschätzungen der Kaderqualität liefern.
Die Integration von Finanzdaten könnte ein weiterer Entwicklungsschritt sein. Der Zusammenhang zwischen Vereinsbudget, Kaderqualität und sportlichem Erfolg ist bekannt, aber noch nicht vollständig in Prognosemodellen abgebildet. Künftige Systeme könnten Finanzkennzahlen nutzen, um die langfristige Wettbewerbsfähigkeit von Vereinen besser einzuschätzen.
Schließlich könnte die Demokratisierung von KI-Tools dazu führen, dass mehr Nutzer Zugang zu hochwertigen Langzeitprognosen haben. Was heute Spezialanbietern vorbehalten ist, könnte morgen als kostenlose App verfügbar sein. Das würde den Wettmarkt effizienter machen, aber auch neuen Nutzern den Einstieg erleichtern.
Unabhängig von der technologischen Entwicklung bleibt die Grundherausforderung bestehen: Die Zukunft ist unsicher, und kein Algorithmus kann diese Unsicherheit vollständig auflösen. KI-Langzeitprognosen werden besser werden, aber sie werden nie perfekt sein. Wer das versteht, kann sie klug nutzen, ohne sich Illusionen hinzugeben.

Ein realistischer Blick auf die Saison
Zum Abschluss ein realistischer Blick auf das, was von KI-Langzeitprognosen für die Champions-League-Saison 2025/26 zu erwarten ist. Die üblichen Verdächtigen werden die Favoritenlisten anführen: Vereine mit tiefen Kadern, erfahrenen Trainern und nachgewiesener Erfolgsgeschichte im Wettbewerb. Die KI wird ihre Siegwahrscheinlichkeiten auf vielleicht zehn bis zwanzig Prozent taxieren, was bedeutet, dass sie in fünf bis zehn simulierten Saisons einmal gewinnen würden.
Gleichzeitig werden Überraschungen passieren. Ein Außenseiter wird unerwartet weit kommen, ein Favorit wird früh scheitern. Die KI wird diese Möglichkeiten als kleine Wahrscheinlichkeiten ausgewiesen haben, und im Nachhinein wird man sagen können, dass das Modell nicht völlig daneben lag, auch wenn es das spezifische Ergebnis nicht vorhergesagt hat.
Der Wert von KI-Langzeitprognosen liegt nicht darin, den Sieger zu erraten. Er liegt darin, die eigene Analyse zu strukturieren, Fehleinschätzungen zu identifizieren und rationale Entscheidungen zu treffen in einem Umfeld, das von Unsicherheit und Emotionen geprägt ist. Wer die Prognosen in diesem Sinne nutzt, wird einen Mehrwert haben, unabhängig davon, ob die konkrete Vorhersage am Ende stimmt oder nicht.
Die Champions League bleibt ein Wettbewerb, in dem das Unerwartete zum Programm gehört. Genau das macht sie so faszinierend, und genau deshalb werden Menschen weiterhin versuchen, das Unvorhersehbare vorherzusagen. KI-Systeme sind dabei hilfreiche Begleiter, aber sie ersetzen nicht das, was den Fußball ausmacht: die Spannung, die Überraschungen und die Geschichten, die kein Algorithmus vorher schreiben konnte.